
Facebook’s big data breach in 2018 sent millions of users into a flurry to reset their Facebook passwords, hoping and praying that their information hadn’t found its way into the wrong hands. Some 50 million Facebook accounts were compromised three days before the company’s announcement, granting hackers access to personal data and landing the social media giant in hot water. Despite damage control efforts, this large-scale hack called into question the overall safety of online accounts.
Big companies are big targets, so it’s no surprise that we only hear about high-profile data breaches. In reality, however, smaller businesses are the ones who are more at risk of being affected by a breach, as they ultimately have much more to lose. When it comes to detecting an attack, researchers from IBM estimate that it takes small businesses about 200 days before a breach is found — and by then, the attack is well under way. It can cost a large amount of money and reputational damage for a business to get back on its feet after a breach, especially when taking into account the time and manpower required to rebuild a company’s operational systems.
All in all, predicting and preventing a data breach is tricky. And while some argue that breaches are inevitable in this day and age, businesses should still arm themselves with the proper tools and information on not only how to prevent a data breach, but also what to do when defenses fail and an attack occurs.
But first, it’s important to know what you might be dealing with. While not all cybersecurity attacks can result in a breach, this article by Chief Executive outlines seven types of data breaches, ranging from hacking via malware and phishing, to employee negligence and physical theft. Being aware of these attacks can help you prevent them, or at least know what to do in the off-chance that your company falls victim.
Category: Data Science

One of the big challenges a data scientist faces is the amount of data that is not in convenient formats. One such format are REST APIs. In large enterprises, these are especially problematic for several reasons. Often a considerable amount of reference data is only accessible via REST API which means that to access this data, users are required to learn enough Python or R to access this data. But what if you don’t want to code?
The typical way I’ve seen this dealt with is to create a duplicate of the reference data in an analytic system such as Splunk or Elasticsearch. The problems with this approach are manifold. First, there is the engineering effort (which costs time and money) to set up the data flow. On top of that, you now have the duplicate cost of storage and now you are maintaining multiple versions of the same information.
Another way I’ve seen is for each API owner to provide a graphical interface for their API, which is good, but the issue there is that now the data is stove-piped and can’t be joined with other data, which defeats its purpose altogether. There has to be a better way…
Take a look at the video tutorial below to see a demo!
As you are reading this, you are probably (like me) under quarantine or shelter in place due to the COVID-19 outbreak. As a data scientist who has been stuck in the house since 10 March, I wanted to take a look at the data and see what I could figure out. I’m not an epidemiologist and claim no expertise in health care, but I do know data science so please take what I am saying with a grain of salt.
Why is there no data?
My first observation is that very little data is actually being made publicly available. I am not sure why this is the case, but I spent a considerable amount of time digging through the WHO, CDC and other agencies’ websites and APIs and found little usable data. For example, the World Health Organization (WHO) posts daily situation reports with data, however the sitreps contain data, however the files are in PDF format. I attempted to extract these tables from the PDFs however this proved to be extremely difficult as the formatting was not consistent. It would be trivial to post this data in CSV, HDF5 or some other format that is conducive to data analysis, however the WHO did not choose to do that. I found generally the same situation at the other major health institutions such as the CDC.
Health related information in the United States is regulated by the Health Insurance Portability and Accountability Act (HIPAA), which imposes draconian fines and restrictions on private health information, so some of the secrecy may be due to this law.
1 Comment
Let me start out by saying this is purely hypothetical as I’ve never been to a data science bootcamp, but I have taught them and have reviewed MANY curricula. I’ve also mentored a decent number of bootcamp graduates. In general, what I see is that bootcamps tend to place a lot of emphasis on machine learning but there’s a lot more to being a successful data scientist. The list below are five areas which I believe would benefit any aspiring data scientist.
SQL
Let’s start with an easy one. SQL. Despite all the trashing that it gets, SQL is an enormously useful language to know. Despite all the hype one hears about NoSQL and other non-relational datastores, SQL is still in widespread use and is not likely to go anywhere anytime soon. Let me tell you why you should learn SQL….
Leave a Comment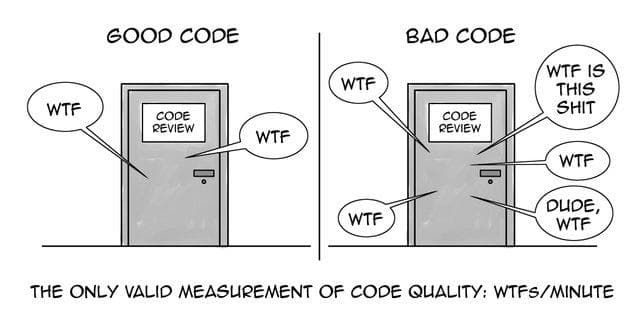
In the early days of data science, many data scientists came with a math background and as a result I think the field took on some bad practices, at least from a computer science perspective. In this post, I’m going to introduce ten coding practices that will help you write better code.
You might say that better is a subjective term, however, I believe that there are concrete measurements to define good vs. bad code.
- Good code is easy to understand and thus will take less time to write and most importantly debug
- Good code is easy to maintain by other people besides the author
- Writing code well will avoid hidden intent errors–ie errors that exist such that your code executes and does what it’s supposed to do most of the time. Intent errors are the worst because your code will appear to work, but all of a sudden, there will be some edge case or something you didn’t think about and now your code breaks. These are the most insidious errors.
- Good code is efficient.
Ultimately, taking on good coding practices will result in fewer errors, which directly translates to more work (value) being delivered and less effort being spent on fixing and maintaining code. Apparently this is a bigger issue than I realized. When I was writing this article, this other article got posted to my Twitter feed: https://insidebigdata.com/2019/08/13/help-my-data-scientists-cant-write-production-code/. I’ll try not to duplicate the points this author made, but in general, the biggest difference that I see between code most data scientists write and production code is that data scientists tend not to think about reusability.
17 CommentsHappy New Year everyone! I’ve been taking a bit of a blog break after completing Learning Apache Drill, teaching a few classes, and some personal travel but I’m back now and have a lot planned for 2019! One of my long standing projects is to get Apache Drill to work with various open source visualization and data flow tools. I attended the Strata conference in San Jose in 2016 where I attended Maxime Beauchemin’s talk (slides available here) where he presented the tool then known as Caravel and I was impressed, really really impressed. I knew that my mission after the conference would be to get this tool to work with Drill. A little over two years later, I can finally declare victory. Caravel went through a lot of evolution. It is now an Apache Incubating project and the name has changed to Apache (Incubating) Superset.
UPDATE: The changes to Superset have been merged, so you can just install Superset as described on their website.
9 Comments
I am currently attending the Splunk .conf in Orlando, and a director at Accenture asked me this question, which I thought merited a blog post. Why don’t data scientists use or like Splunk. The inner child in me was thinking, “Splunk isn’t good at data science”, but the more seasoned professional in me actually articulated a more logical and coherent answer, which I thought I’d share whilst waiting for a talk to start. Here goes:
I cannot pretend to speak for any community of “data scientists” but it is true that I know a decent number of data scientists, some very accomplished and some beginners, and not a one would claim to use Splunk as one of their preferred tools. Indeed, when the topic of available tools comes up among most of my colleagues and the word Splunk is mentioned, it elicits groans and eye rolls. So let’s look at why that is the case:
9 Comments
Last Friday, the Apache Drill released Drill version 1.14 which has a few significant features (plus a few that are really cool!) that will enable you to use Drill for analyzing security data. Drill 1.14 introduced:
- A logRegex reader which enables Drill to read anything you can describe with a Regex
- An image metadata reader, which enables you to query images
- A suite a of GIS functionality
- A collection of phonetic and string distance functions which can be used for approximate string matching.
These suite of functionality really expands what is possible with Drill, and makes analysis of many different types of data possible. This brief tutorial will walk you through how to configure Apache Drill to query log files, or any file really that can be matched with a regex.
1 Comment
In the last week, beneath all the Trump and Kim Jong Un reporting, were several stories that state that Apple has in effect declared war on data collectors. Make no mistake, what Apple is doing is making it significantly harder for companies big and small to collect your personal data. The significance of this cannot be overstated in that many companies like Google and Facebook’s revenue is based on selling targeted advertising and if gathering this data becomes significantly more difficult, it could affect their bottom lines.
The First Volley: No More Comments and Share Buttons
 Last week, I was listening to the keynotes at the WWDC, and overall was pretty unimpressed as exec after exec droned on about new animojis or some other feature that I really didn’t care about, and then, Craig Federighi launched the first volley: Safari is going to block FaceBook and other social media like and share buttons as well as shared comment sections. Facebook, Twitter and other sites use these buttons to track your activity when you are visiting other sites. While it isn’t that big of a deal that this is happening on MacOS, it is VERY significant that Apple is instituting this change on iOS as well. When I heard this, I was pretty shocked, but that was only the first volley, there were more to come.
Last week, I was listening to the keynotes at the WWDC, and overall was pretty unimpressed as exec after exec droned on about new animojis or some other feature that I really didn’t care about, and then, Craig Federighi launched the first volley: Safari is going to block FaceBook and other social media like and share buttons as well as shared comment sections. Facebook, Twitter and other sites use these buttons to track your activity when you are visiting other sites. While it isn’t that big of a deal that this is happening on MacOS, it is VERY significant that Apple is instituting this change on iOS as well. When I heard this, I was pretty shocked, but that was only the first volley, there were more to come.

I’ve been waiting for some time to publish this, but I wanted to write about my experiences interviewing for data science jobs. Here’s my story, I worked at Booz Allen for nearly seven years but I felt it was time for a change. I very much like Booz Allen as a company and if anyone is interested in working there, please don’t hesitate to contact me. But I felt I was ready for different challenges and started looking for work elsewhere.
Now that I started a new position, I thought I’d share some observations about what I learned from interviewing at numerous companies. I wasn’t tracking how many companies I interviewed with, but it was a lot. I have a lot of government experience and got a number of offers from government contracting firms. However, I came to the conclusion that in terms of career progression, joining another government contracting firm was not what I was looking for.
So here’s what I learned…
1 Comment