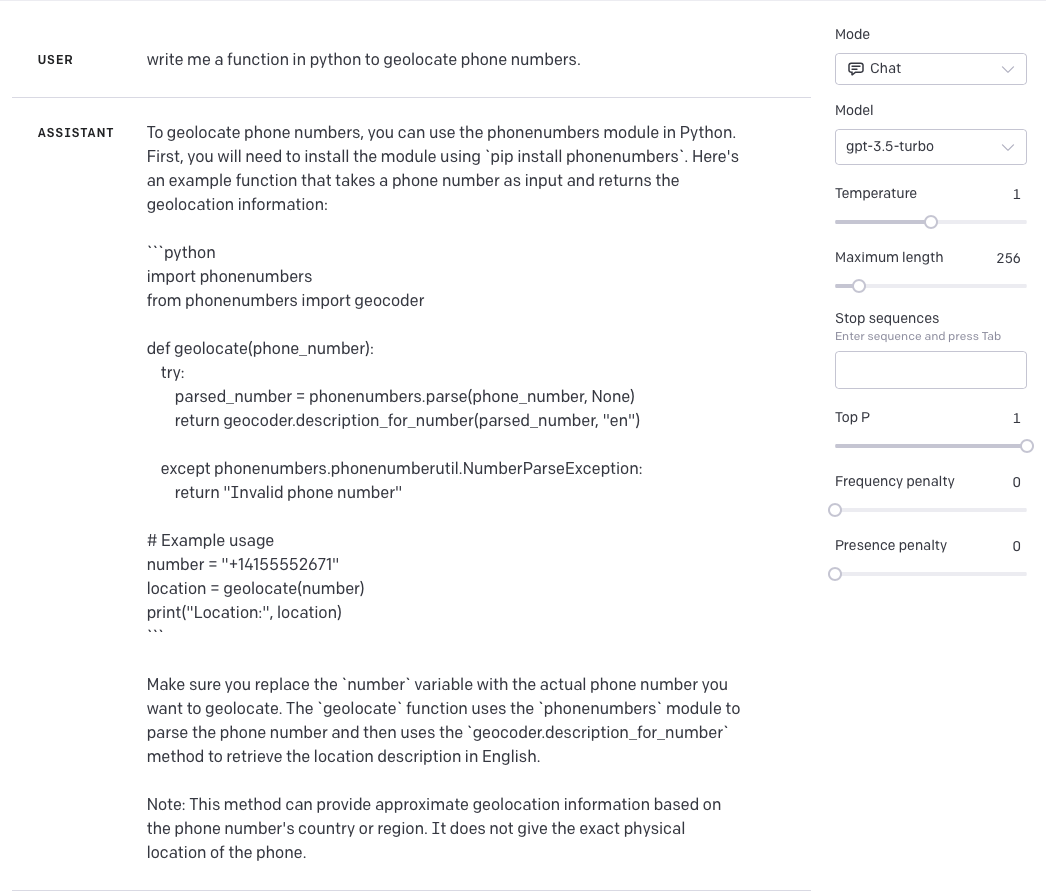
A lot of people have tried out ChatGPT and other LLMs for code their code writing abilities. My theory was that the LLMs would be really good at writing code to do things they’ve seen before, but not so good at things that were completely new. I started my experiments by asking ChatGPT to write me a function in python to geolocate a phone number. ChatGPT 3.5 did a relatively poor job of this, so I tried again using the playground and gpt-3.5-turbo. This time it was more successful.
That’s not bad. I like that it used the phonenumbers library rather than calling some external service.
Googlesheets (GS) is one of those data sources that I think most data scientists use and probably dread a little. Using GS is easy enough, but what if a client gives you data in GS? Or worse, what if they have a lot of data in GS and other data that isn’t? Personally, whenever I’ve encountered data in GS, I’ve usually just downloaded it as a CSV and worked on it from there. This works fine, but if you have to do something that requires you to pull this data programmatically? This is where it gets a lot harder. This article will serve as both a rant and tutorial for anyone who is seeking to integrate GoogleSheets into their products.
I decided that it would be worthwhile to write a connector (plugin) for Apache Drill to enable Drill to read and write Google Sheets. After all, after Excel, they are probably one of the most common ways people store tabular data. We’ve really wanted to integrate GoogleSheets into DataDistillr as well, so this seemed like a worthy project. You can see this in action here:
So where to start?
Aha! You say… Google provides an API to access GS documents! So what’s the problem? The problem is that Google has designed what is quite possibly one of the worst SDKs I have ever seen. It is a real tour de force of terrible design, poor documentation, inconsistent naming conventions, and general WTF.
To say that this was an SDK designed by a committee is giving too much credit to committees. It’s more like a committee who spoke one language, hired a second committee which spoke another language to retain development teams which would never speak with each other to build out the API in fragments.
As you’ll see in a minute, the design decisions are horrible, but this goes far beyond bad design. The documentation, when it exists, is often sparse, incomplete, incoherent or just plain wrong. This really could be used as an exemplar of how not to design SDKs. I remarked to my colleague James who did the code review on the Drill side, that you can tell when I developed the various Drill components as the comments get snarkier and snarkier.
It seems I always start my posts with “it’s been a while since I last posted…”. Well, it has. The truth is that during the month of April, I did something I hadn’t done in a while: took a vacation. That was nice, but then I got COVID (not fun), which everyone in my household got. Then I went to Singapore. More on that later. I’ve also been very heads down with some coding and technical stuff relating to security on our startup. I’ll tell you all about that in part 15. Anyway… I wanted to share a long overdue update.
A week ago, I posted a LinkedIn poll where I asked the question: “How many of you use Excel or GoogleSheets as a database?” In my extremely unscientific poll, about 45% of the responses said that they did. Indeed, this poll mirrors my experience in talking with customers in that despite massive corporate investments in platforms like Snowflake, Splunk, data lakes, delta lakes, lake houses, tons of work is done in Excel. The result is that for many organizations, a significant amount of their most valuable data isn’t in their data lake.
Facebook’s big data breach in 2018 sent millions of users into a flurry to reset their Facebook passwords, hoping and praying that their information hadn’t found its way into the wrong hands. Some 50 million Facebook accounts were compromised three days before the company’s announcement, granting hackers access to personal data and landing the social media giant in hot water. Despite damage control efforts, this large-scale hack called into question the overall safety of online accounts.
Big companies are big targets, so it’s no surprise that we only hear about high-profile data breaches. In reality, however, smaller businesses are the ones who are more at risk of being affected by a breach, as they ultimately have much more to lose. When it comes to detecting an attack, researchers from IBM estimate that it takes small businesses about 200 days before a breach is found — and by then, the attack is well under way. It can cost a large amount of money and reputational damage for a business to get back on its feet after a breach, especially when taking into account the time and manpower required to rebuild a company’s operational systems.
All in all, predicting and preventing a data breach is tricky. And while some argue that breaches are inevitable in this day and age, businesses should still arm themselves with the proper tools and information on not only how to prevent a data breach, but also what to do when defenses fail and an attack occurs.
But first, it’s important to know what you might be dealing with. While not all cybersecurity attacks can result in a breach, this article by Chief Executive outlines seven types of data breaches, ranging from hacking via malware and phishing, to employee negligence and physical theft. Being aware of these attacks can help you prevent them, or at least know what to do in the off-chance that your company falls victim.