A colleague of mine recently gave me a data challenge called the Hanukkah of Data (https://hanukkah.bluebird.sh/about/) which has 8 challenges. I decided to try them out in DataDistillr. The challenges use a fictional data set which consists of four tables: a customer table, a product table, an order table and a table linking orders to products. The data was very representative of what a customer database might look like. I did, however make some modifications to the data to facilitate querying. The address line was not split up into city, state, zip. So I imported this data into a database, and then split these fields up into separate columns.
Overall, this was a really well done challenge and my compliments to the authors.
SPOILER ALERT
If you choose to read beyond this point, it will have my answers so if you want to try it yourself, stop right here. I warned you… Really … go no further.
Googlesheets (GS) is one of those data sources that I think most data scientists use and probably dread a little. Using GS is easy enough, but what if a client gives you data in GS? Or worse, what if they have a lot of data in GS and other data that isn’t? Personally, whenever I’ve encountered data in GS, I’ve usually just downloaded it as a CSV and worked on it from there. This works fine, but if you have to do something that requires you to pull this data programmatically? This is where it gets a lot harder. This article will serve as both a rant and tutorial for anyone who is seeking to integrate GoogleSheets into their products.
I decided that it would be worthwhile to write a connector (plugin) for Apache Drill to enable Drill to read and write Google Sheets. After all, after Excel, they are probably one of the most common ways people store tabular data. We’ve really wanted to integrate GoogleSheets into DataDistillr as well, so this seemed like a worthy project. You can see this in action here:
So where to start?
Aha! You say… Google provides an API to access GS documents! So what’s the problem? The problem is that Google has designed what is quite possibly one of the worst SDKs I have ever seen. It is a real tour de force of terrible design, poor documentation, inconsistent naming conventions, and general WTF.
To say that this was an SDK designed by a committee is giving too much credit to committees. It’s more like a committee who spoke one language, hired a second committee which spoke another language to retain development teams which would never speak with each other to build out the API in fragments.
As you’ll see in a minute, the design decisions are horrible, but this goes far beyond bad design. The documentation, when it exists, is often sparse, incomplete, incoherent or just plain wrong. This really could be used as an exemplar of how not to design SDKs. I remarked to my colleague James who did the code review on the Drill side, that you can tell when I developed the various Drill components as the comments get snarkier and snarkier.
People often ask me questions about starting a career in data science or for advice what tech skills they should acquire. When I get asked this question, I try to have a conversation with the person to see what their goals and aspirations are as there’s no advice that I can give that is universal, here are five pointers that I would say are generally helpful for anyone starting a career in data science or data analytics.
Tip 1: Data Science is a Big Field: You Can’t Know Everything About Everything:
When you start getting into data science, the breadth of the field can be overwhelming. It seems that you have to be an expert in big data systems, relational databases, computer sciences, linear algebra, statistics, machine learning, data visualization, data engineering, SQL, Docker, Kubernetes, and much more. To say nothing about subject matter expertise. One of the big misunderstandings I see is the perception that you have to be an expert in all these areas to get your first job.
One of the big challenges a data scientist faces is the amount of data that is not in convenient formats. One such format are REST APIs. In large enterprises, these are especially problematic for several reasons. Often a considerable amount of reference data is only accessible via REST API which means that to access this data, users are required to learn enough Python or R to access this data. But what if you don’t want to code?
The typical way I’ve seen this dealt with is to create a duplicate of the reference data in an analytic system such as Splunk or Elasticsearch. The problems with this approach are manifold. First, there is the engineering effort (which costs time and money) to set up the data flow. On top of that, you now have the duplicate cost of storage and now you are maintaining multiple versions of the same information.
Another way I’ve seen is for each API owner to provide a graphical interface for their API, which is good, but the issue there is that now the data is stove-piped and can’t be joined with other data, which defeats its purpose altogether. There has to be a better way…
Take a look at the video tutorial below to see a demo!
The image above is a late 50’s MGA convertible. I picked this because I happen to think that this car is one of the most elegantly designed cars ever made. Certainly in the top 50. While we as people place a lot of emphasis on design when it comes to physical objects that we use, when it comes to software, a lot of our software’s design looks more like the car below: This vehicle looks like it was designed by a committee that couldn’t decide whether they were designing a door stop or a golf cart.
I’ve been doing a lot of thinking lately (for reasons that will become apparent in a few weeks) about the lack of good software engineering practices in the data science space. The more I think about it, the more I am shocked with the questionable design that exists in the data science ecosystem, particularly in Python. What’s even more impressive is that the python language is actually designed to promote good design, and the people building these modules are all great developers.
As an example of this, I recently read an article about coding without if statements and it made me cringe. Here is a quote:
When I teach beginners to program and present them with code challenges, one of my favorite follow-up challenges is: Now solve the same problem without using if-statements (or ternary operators, or switch statements).
You might ask why would that be helpful? Well, I think this challenge forces your brain to think differently and in some cases, the different solution might be better.
There is nothing wrong with using if-statements, but avoiding them can sometimes make the code a bit more readable to humans. This is definitely not a general rule as sometimes avoiding if-statements will make the code a lot less readable. You be the judge.
Well, I am going to be the judge and every example the author cited made the code more difficult to follow. The way I see it, hard to follow code means that you as the developer are more likely to introduce unintended bugs and errors. Since the code is difficult to follow, not only will you have more bugs, but these bugs will take you more time to find. Even worse, if you didn’t write this code and are asked to debug it!! AAAAHHHH!! I know if that were me, I wouldn’t even bother. I’d probably just rewrite it. The only exception would be if it was heavily commented.
Let me start out by saying this is purely hypothetical as I’ve never been to a data science bootcamp, but I have taught them and have reviewed MANY curricula. I’ve also mentored a decent number of bootcamp graduates. In general, what I see is that bootcamps tend to place a lot of emphasis on machine learning but there’s a lot more to being a successful data scientist. The list below are five areas which I believe would benefit any aspiring data scientist.
SQL
Let’s start with an easy one. SQL. Despite all the trashing that it gets, SQL is an enormously useful language to know. Despite all the hype one hears about NoSQL and other non-relational datastores, SQL is still in widespread use and is not likely to go anywhere anytime soon. Let me tell you why you should learn SQL….
I ran into an issue whilst doing a machine learning project involving some categorical data and thought I would write a brief tutorial about what I learned. I was working on a model which had a considerable amount of categorical data and I ran into several issues which can briefly be summarized as:
Categories that were present in the training set were not always present in the testing data
Categories that were present in the testing set were not always present in the training data
Categories from “real world” (IE non testing or training) data were not present in the training or testing data
Handling Categorial Data: A brief tutorial
In Python, one of the unfortunate things about the scikit-learn/pandas modules is that they don’t really deal with categorical data very well. In the last few years, the Pandas community has introduced a “categorical” datatype. Unfortunately, this datatype does not carry over to scikit-learn, so if you have categorical data, you still have to encode it. Now there are tons of tutorials on the interweb about how to do this, so in the interests of time, I’ll show you the main methods:
GetDummies in Pandas
The most conventional approach and perhaps the easiest is pandas get_dummies() function which takes the input of a given column or columns and returns dummy columns for each category value. (Full docs here). Thus you can do the following:
df = pd.get_dummies(df)
data
0
a
1
b
2
c
3
a
4
a
5
a
6
c
7
c
8
c
data_a
data_b
data_c
0
1
0
0
1
0
1
0
2
0
0
1
3
1
0
0
4
1
0
0
5
1
0
0
6
0
0
1
7
0
0
1
8
0
0
1
Which turns the table on the left into the table on the right.
As you can see, each category is encoded into a separate column with the column name followed by an underscore and the category variable. If the data is a member of that category, the column has a value of 1 otherwise the value is zero, hence the name One Hot Encoding.
In general this works, but the pandas method has the problem of not working as a part of a Scikit-Learn pipeline. As such scikit-learn also has a OneHotEncoder which you can use to do basically the same thing.
Personally, I find scikit’s OneHotEncoder to be a bit more difficult to use, so I didn’t really use it much, however, in my recent project I realized that I actually had to for a reason I’ll get to in a bit.
Scikit Learn’s OneHotEncoder
Scikit-Learn has the OneHotEncoder() (Docs here) which does more or less the same thing as the pandas version. It does have several limitations, and quirks. The first being that the data types of your categories must be the same. IE if you have ints and strings, no go.. Secondly, scikit’s encoder returns either a numpy array or a sparse matrix as a result. Personally, this was annoying for me as I wanted to see what categories were useful as features, and in order to do so, you have to reconstruct a dataframe, which is a headache. In general, the code follows scikit’s general pattern of fit(), transform(). Here is example code of how to use scikit’s one hot encoder:
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(handle_unknown='ignore')
encoded_data = encoder.fit_transform(df[<category_columns>])
There are two advantages that I see that scikit’s method has over pandas. The first is that when you fit the scikit encoder, it now “remembers” what categories it has seen, and you can set it to ignore unknown categories. Whereas pandas does not have any recall and will just automatically convert all columns to dummy variables. The second is that you could include the OneHotEncoder in a pipeline which seemed like that would be advantageous as well. However, these advantages did not outweigh the difficulty of getting the data back into a dataframe with column labels. Also, I kept getting errors relating to datatypes and got really frustrated.
The original problem I was having was that you couldn’t guarantee that all categories would be present in both the training and testing set, so the solution I came up with was to write a function that switched the category value to “OTHER” if the category was not one of the top few. But I didn’t like this approach because it required me to maintain a list of categories and what happened if that list changed over time? Surely there’s a better way…
Feature-Engine: A Better Solution
So what if I told you there was a way to encode categorical data such that you could:
Handle missing categories in either testing, training or real world data
Export the data to a DataFrame for easy analysis of the newly created features
Automatically aggregate categories with few values into an “other” category
Well you can’t so get over it. Ok, just kidding. I wouldn’t write a whole blog post to have it end like that… or would I? As it turns out, I stumbled upon a really useful module called feature-engine which contains some extremely useful tools for feature engineering that frankly should be included in Scikit-Learn. This module contains a collection of really useful stuff, but I’m just going to focus on the OneHotCategoryEncoder. (Docs here)
Let’s say you wanted to encode the data above, using the OneHotCategoryEncoder() you could create an encoder object as shown below:
from feature_engine import categorical_encoders as ce
import pandas as pd
# set up the encoder
encoder = ce.OneHotCategoricalEncoder(
top_categories=3,
drop_last=False)
# fit the encoder
encoder.fit(df)
encoder.transform(df)
Now, once we have the encoder object, we can encode our data using the fit()/transform() or the fit_transform() methods as shown above. Our toy data set above only has 3 categories, but what if it had 300? Feature-Engine provides an option in the constructor, top_categories, which has the effect of collapsing the into a more manageable number. For example, you could set the top_categories to 10 and that would get you the 10 most frequently occurring category columns and all others would be collapsed into an “other” column. That’s a nice feature! Well done!
There’s more. In our previous example, we had three categories when we fit the data, ‘A’, ‘B’ and ‘C’. So what happens if we have another category in the data that did not appear in the training data? Good question, and one that is not explicitly addressed in the documentation. So I tried this out and if you have the top_categories set, the encoder will ignore the unknown categories. This is debatable as to whether this is good design or not, but what it does mean is that it will work much better in real world applications.
Since the OneHotCategoricalEncoder uses the fit()/fit_transform()/transform() from scikit-learn, it can be used in a Pipeline object. Finally, and perhaps most important to me, is that the OneHotCategoricalEncoder returns a pandas DataFrame rather than numpy arrays or other sparse matrices. The reason this mattered to me was that I wanted to see which categorical columns actually are adding value to the model and which are not. Doing this from a numpy array without column references is exceedingly difficult.
TL;DR
In conclusion, both scikit-learn and Pandas traditional ways of encoding categorical variables have significant disadvantages, so if you have categorical data in your model, I would strongly recommend taking a look at Feature-Engine’s OneHotCategoricalEncoder.
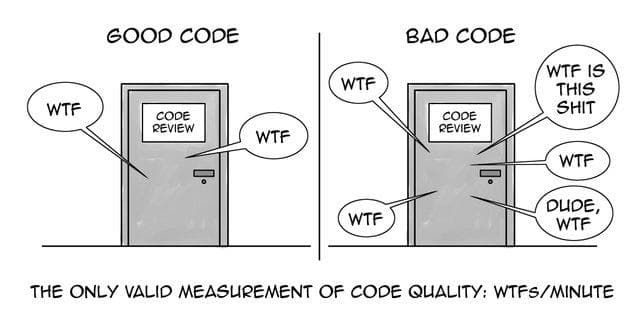
In the early days of data science, many data scientists came with a math background and as a result I think the field took on some bad practices, at least from a computer science perspective. In this post, I’m going to introduce ten coding practices that will help you write better code.
You might say that better is a subjective term, however, I believe that there are concrete measurements to define good vs. bad code.
Good code is easy to understand and thus will take less time to write and most importantly debug
Good code is easy to maintain by other people besides the author
Writing code well will avoid hidden intent errors–ie errors that exist such that your code executes and does what it’s supposed to do most of the time. Intent errors are the worst because your code will appear to work, but all of a sudden, there will be some edge case or something you didn’t think about and now your code breaks. These are the most insidious errors.
Good code is efficient.
Ultimately, taking on good coding practices will result in fewer errors, which directly translates to more work (value) being delivered and less effort being spent on fixing and maintaining code. Apparently this is a bigger issue than I realized. When I was writing this article, this other article got posted to my Twitter feed: https://insidebigdata.com/2019/08/13/help-my-data-scientists-cant-write-production-code/. I’ll try not to duplicate the points this author made, but in general, the biggest difference that I see between code most data scientists write and production code is that data scientists tend not to think about reusability.
Happy New Year everyone! I’ve been taking a bit of a blog break after completing Learning Apache Drill, teaching a few classes, and some personal travel but I’m back now and have a lot planned for 2019! One of my long standing projects is to get Apache Drill to work with various open source visualization and data flow tools. I attended the Strata conference in San Jose in 2016 where I attended Maxime Beauchemin’s talk (slides available here) where he presented the tool then known as Caravel and I was impressed, really really impressed. I knew that my mission after the conference would be to get this tool to work with Drill. A little over two years later, I can finally declare victory. Caravel went through a lot of evolution. It is now an Apache Incubating project and the name has changed to Apache (Incubating) Superset.
UPDATE: The changes to Superset have been merged, so you can just install Superset as described on their website.
Last Friday, the Apache Drill released Drill version 1.14 which has a few significant features (plus a few that are really cool!) that will enable you to use Drill for analyzing security data. Drill 1.14 introduced:
A logRegex reader which enables Drill to read anything you can describe with a Regex
An image metadata reader, which enables you to query images
A suite a of GIS functionality
A collection of phonetic and string distance functions which can be used for approximate string matching.
These suite of functionality really expands what is possible with Drill, and makes analysis of many different types of data possible. This brief tutorial will walk you through how to configure Apache Drill to query log files, or any file really that can be matched with a regex.