
I teach a graduate level data management class at the University of Maryland, Baltimore County (UMBC). Let me preface this by saying that the midterm and final exams for my course are all online, open book, open notes. Despite this, and despite all my warnings about the dire consequences of plagiarism, I routinely catch students cheating on exams. I really love teaching, and it is very disheartening for me when I have to dole out the consequences for this behavior. Usually, cheating comes in the form of students copying answers from the internet without attribution or from other students. This semester was different. This semester, students had AI.
Leave a CommentCategory: General Thoughts

I’ve had a number of conversations recently that have highlighted to me how not understanding people’s assumptions can really hamper conversations. I’m going to highlight questions from two recent conversations, one was with a VC and the other was from a grant for which we applied. My biggest frustration in all this is that how wrong assumptions on both parties prevented deals from moving forward. I assumed that the other parties understood what I understood about SQL, which was wrong. The other parties’ assumptions about what you couldn’t do with SQL led them to assume other things about DataDistillr that was also wrong. In any event, it was the assumptions that bit us both.
Today’s SQL is not What You Learned in 1996
We applied for a US Government grant which unfortunately we did not win. The feedback seemed to center around whether or not SQL was capable of dealing with multi-dimensional data. The reviewers seemed to think that this was not possible and would be extremely difficult. Here’s where the assumptions hurt. I assumed that the reviewer would know that modern SQL tools already support multidimensional data structures. The reviewer assumed the opposite based on their understanding of SQL. It was a lesson learned for me in that I should have put more explanatory language explaining current state. I wish however, that we could have spoken with the reviewer and explained this.
Yes, SQL Supports Nested Data
Unfortunately, SQL hasn’t coalesced around a solid standard for this, but many SQL based systems such as Drill, Spark, Presto, Postgres, MySQL and many others support querying nested data using SQL.
Leave a Comment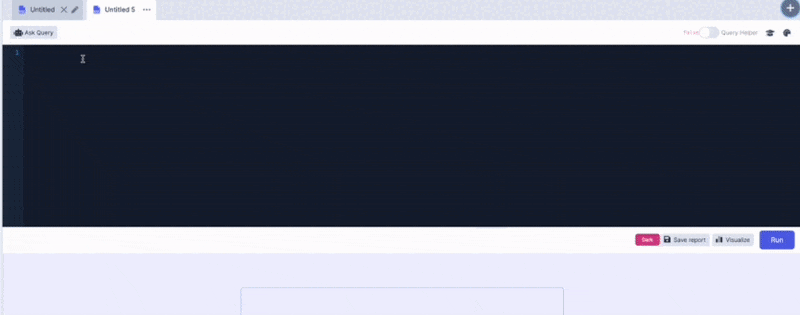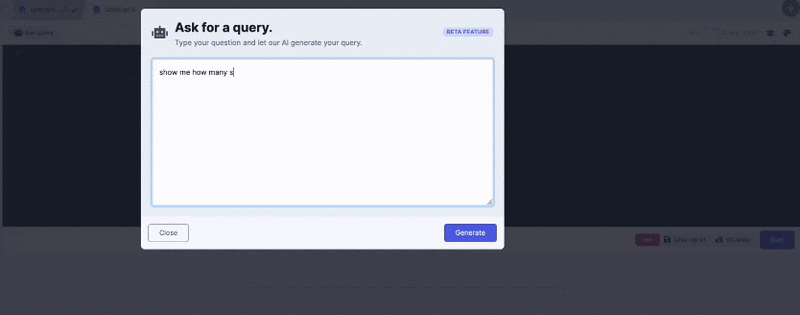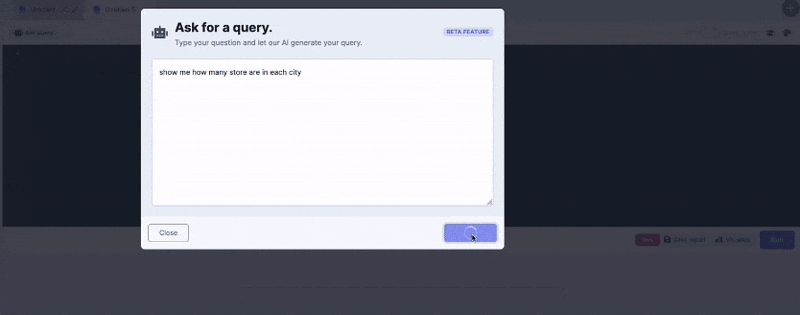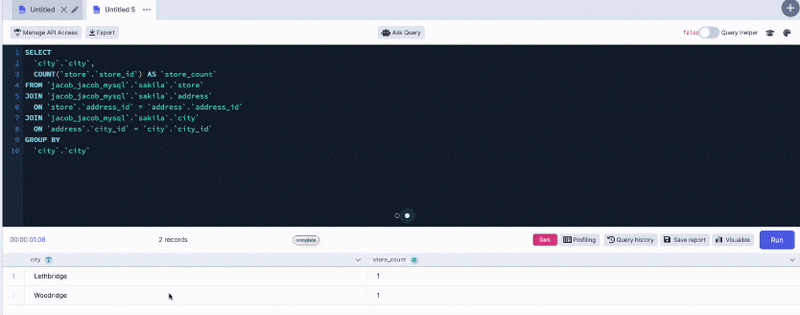
Happy New Year everyone! I’m pretty excited about this. Like every other tech geek out there, I was experimenting with ChatGPT when it was announced in December of 2022.
Initially I was amazed at how well the AI appeared to work, and somewhat terrified with what people could actually do with it. I teach a database class at the University of Maryland Baltimore County (UMBC) and I was really worried that students could use ChatGPT to generate answers to essay questions on my exams. I wanted to see if there were ways of phrasing questions that would make it obvious that a person did not write them. After using ChatGPT for a while, I do think it would be possible to detect if a student was using AI to write their papers, as the quality and style are fairly distinct.
But I digress…
What really intrigued me was that these models can write SQL queries using natural language. Of course the fact that you can write a SQL query isn’t necessarily useful unless you understand the schema of the underlying data and you have a query engine or database capable of executing that query.
Well… guess what…
My team and I have been hard at work at incorporating this powerful feature into our DataDistillr. Today, I am happy to announce that we’ve added natural language AI capability to DataDistillr!
Leave a Comment
This is going to piss people off. I took a road trip a few weeks ago to New York and listened to an interview with Mark Zuckerberg where he discussed the Metaverse and Meta’s plans for it. The whole time I was thinking… this is complete bullshit. I feel that in the tech world there is so much bullshit out there, that I really needed to write a post about it and share my views on the subject.
My criteria for bullshit tech are:
- Over hyped in relationship to actual usefulness
- Over hyped in terms of current state of technology and unlikely to realize the vision in a reasonable amount of time.
- Unlikely to provide any real value in the near term
- A gigantic waste of time and money
These are listed in no particular order…
Leave a Comment
People often ask me questions about starting a career in data science or for advice what tech skills they should acquire. When I get asked this question, I try to have a conversation with the person to see what their goals and aspirations are as there’s no advice that I can give that is universal, here are five pointers that I would say are generally helpful for anyone starting a career in data science or data analytics.
Tip 1: Data Science is a Big Field: You Can’t Know Everything About Everything:
When you start getting into data science, the breadth of the field can be overwhelming. It seems that you have to be an expert in big data systems, relational databases, computer sciences, linear algebra, statistics, machine learning, data visualization, data engineering, SQL, Docker, Kubernetes, and much more. To say nothing about subject matter expertise. One of the big misunderstandings I see is the perception that you have to be an expert in all these areas to get your first job.
2 Comments
Today marks about the 45th day I’ve been stuck in the house and it happens that my birthday was last week, so I’ve been doing a lot of reading and reflecting on things. The last few weeks have been really up and down. I’ve been doing a lot of puttering around the house and working on silly projects like replacing the headlight gaskets on my MGA, which also involved painting the headlight buckets, cutting off rusty screws and redoing wiring, but I digress. Despite being home all the time, I’m finding it very difficult to get any meaningful work done.


After
On the up side, I’ll be doing some new online classes with O’Reilly starting around the end of May! The topics relate to coding practices and data visualization, so stay tuned!
Leave a Comment
As you are reading this, you are probably (like me) under quarantine or shelter in place due to the COVID-19 outbreak. As a data scientist who has been stuck in the house since 10 March, I wanted to take a look at the data and see what I could figure out. I’m not an epidemiologist and claim no expertise in health care, but I do know data science so please take what I am saying with a grain of salt.
Why is there no data?
My first observation is that very little data is actually being made publicly available. I am not sure why this is the case, but I spent a considerable amount of time digging through the WHO, CDC and other agencies’ websites and APIs and found little usable data. For example, the World Health Organization (WHO) posts daily situation reports with data, however the sitreps contain data, however the files are in PDF format. I attempted to extract these tables from the PDFs however this proved to be extremely difficult as the formatting was not consistent. It would be trivial to post this data in CSV, HDF5 or some other format that is conducive to data analysis, however the WHO did not choose to do that. I found generally the same situation at the other major health institutions such as the CDC.
Health related information in the United States is regulated by the Health Insurance Portability and Accountability Act (HIPAA), which imposes draconian fines and restrictions on private health information, so some of the secrecy may be due to this law.
1 Comment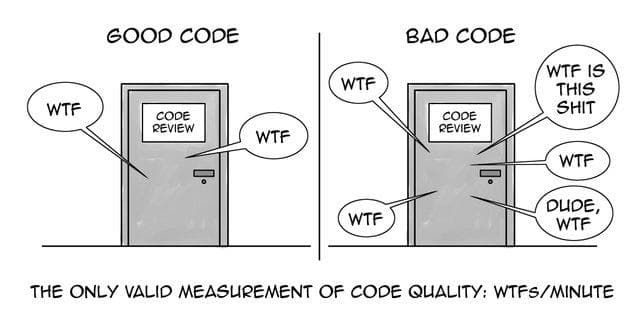
In the early days of data science, many data scientists came with a math background and as a result I think the field took on some bad practices, at least from a computer science perspective. In this post, I’m going to introduce ten coding practices that will help you write better code.
You might say that better is a subjective term, however, I believe that there are concrete measurements to define good vs. bad code.
- Good code is easy to understand and thus will take less time to write and most importantly debug
- Good code is easy to maintain by other people besides the author
- Writing code well will avoid hidden intent errors–ie errors that exist such that your code executes and does what it’s supposed to do most of the time. Intent errors are the worst because your code will appear to work, but all of a sudden, there will be some edge case or something you didn’t think about and now your code breaks. These are the most insidious errors.
- Good code is efficient.
Ultimately, taking on good coding practices will result in fewer errors, which directly translates to more work (value) being delivered and less effort being spent on fixing and maintaining code. Apparently this is a bigger issue than I realized. When I was writing this article, this other article got posted to my Twitter feed: https://insidebigdata.com/2019/08/13/help-my-data-scientists-cant-write-production-code/. I’ll try not to duplicate the points this author made, but in general, the biggest difference that I see between code most data scientists write and production code is that data scientists tend not to think about reusability.
17 Comments
I am currently attending the Splunk .conf in Orlando, and a director at Accenture asked me this question, which I thought merited a blog post. Why don’t data scientists use or like Splunk. The inner child in me was thinking, “Splunk isn’t good at data science”, but the more seasoned professional in me actually articulated a more logical and coherent answer, which I thought I’d share whilst waiting for a talk to start. Here goes:
I cannot pretend to speak for any community of “data scientists” but it is true that I know a decent number of data scientists, some very accomplished and some beginners, and not a one would claim to use Splunk as one of their preferred tools. Indeed, when the topic of available tools comes up among most of my colleagues and the word Splunk is mentioned, it elicits groans and eye rolls. So let’s look at why that is the case:
9 Comments
I recently completed Technically Wrong by Sara Wachter-Boettcher. Let me start by saying that I’m glad that Ms. Wachter-Boettcher wrote this book. The tech industry has a lot of issues which need to be brought out into the open and it is definitely a positive development that people such as Ms. Wachter-Boettcher are bringing these issues to the forefront. It really is only recently that people are discussing the continuous erosion of privacy, misogyny in the tech industry, lack of diversity and many other issues. Whilst I would not deny any of these issues, I felt Wachter-Boettcher’s analysis was somewhat lacking and didn’t really get at the realities of working in the tech industry. Wachter-Boettcher cites numerous examples of tech gone wrong, such as a smart scale telling a two year old that he needs to lose weight, FaceBook denying a Native American person an account because it felt that their name was not legitimate, and the abhorrent use of proprietary, black box algorithms to make parole recommendations.
Again, it is definitely a positive development that Wachter-Boettcher and others are writing about these issues, but the alternatives and solutions she proposes seem a bit simplistic. While she doesn’t state this directly, much of the book seems to suggest that all of technology’s woes are caused by the lack of diversity in the tech industry. Specifically that “white guys” from elite universities are running everything. I don’t have an electronic copy of the book, but after about half way through this, I wanted to count the number of times the phrase “white guys” appears in the book. Sometimes this phrase includes Asians, sometimes not.
Leave a Comment