As you are reading this, you are probably (like me) under quarantine or shelter in place due to the COVID-19 outbreak. As a data scientist who has been stuck in the house since 10 March, I wanted to take a look at the data and see what I could figure out. I’m not an epidemiologist and claim no expertise in health care, but I do know data science so please take what I am saying with a grain of salt.
Why is there no data?
My first observation is that very little data is actually being made publicly available. I am not sure why this is the case, but I spent a considerable amount of time digging through the WHO, CDC and other agencies’ websites and APIs and found little usable data. For example, the World Health Organization (WHO) posts daily situation reports with data, however the sitreps contain data, however the files are in PDF format. I attempted to extract these tables from the PDFs however this proved to be extremely difficult as the formatting was not consistent. It would be trivial to post this data in CSV, HDF5 or some other format that is conducive to data analysis, however the WHO did not choose to do that. I found generally the same situation at the other major health institutions such as the CDC.
Health related information in the United States is regulated by the Health Insurance Portability and Accountability Act (HIPAA), which imposes draconian fines and restrictions on private health information, so some of the secrecy may be due to this law.
In any event, the data that seems to have become the de facto standard for the coronavirus outbreak is the interactive map by Johns Hopkins Coronavirus Resource Center. CSSE was more generous than other organizations and posted some of their data to github which is available here. The issue with this data is that while it is in CSV format (Thank you!) it is not especially clean or in a format that facilitates analysis. I wrote a little script which I posted below that cleans up the CSSE data a bit, specifically putting all the dates into a consistent format, making all the stats integers and filling blanks with zeros. Feel free to use this if you want.
import pandas as pd
import glob
import os
import re
BASE_PATH = "<path to data>"
DATA_PATH = "csse_covid_19_data/csse_covid_19_daily_reports"
'''
Transform all dates into dates formatted yyyy-mm-dd
'''
def dateFixer(d):
pattern1 = r'([0-9]{1,2})/([0-9]{1,2})/([0-9]{4})'
pattern2 = r'1/([0-9]{2})/20 '
matchObj = re.match(pattern1, d)
matchObj2 = re.match(pattern2, d)
if matchObj:
newDate = matchObj.group(3) + "-0" + matchObj.group(1) + "-" + matchObj.group(2)
elif matchObj2:
newDate = "2020-01-" + matchObj2.group(1)
else:
newDate = d[0:10]
return newDate
# Iterate over data files
for filename in glob.glob(os.path.join(BASE_PATH, DATA_PATH, '*.csv')):
with open(filename, 'r') as f
# Open each data file
df = pd.read_csv(filename)
# Convert all dates to YYYY-MM-DD Format
df['Last Update'] = df['Last Update'].apply(dateFixer)
# Clean up stats columns, convert all to ints and fill blanks with zeros
df['Confirmed'] = df['Confirmed'].fillna(0).astype('int64')
df['Deaths'] = df['Deaths'].fillna(0).astype('int64')
df['Recovered'] = df['Recovered'].fillna(0).astype('int64')
# Save as CSV
df.to_csv(filename, index=False)
Still Little Information…
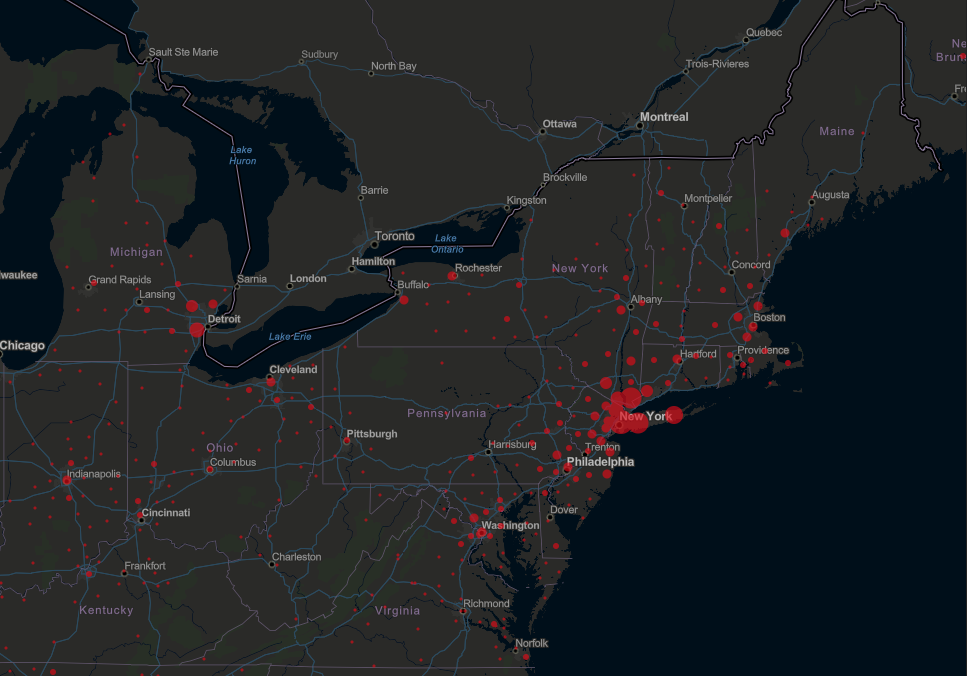
As mentioned earlier, the de facto source of information about the outbreak is the interactive map published by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University (JHU). While this infographic is visually appealing, I would suggest at the authors could do a lot more with the data they have available.
First, let’s take a look at the dots which indicate the areas of outbreak. Until today (March 23), reporting in the US was at the state level, so it was difficult to see exactly where in the country there were outbreaks. In the image on the left, if you compare the dot on eastern Long Island (Suffolk County), with the dot for Detroit, you’d see that they look about the same. However, metro Detroit (Wayne County) has 477 confirmed cases, whereas Suffolk County New York has 1034 confirmed cases.
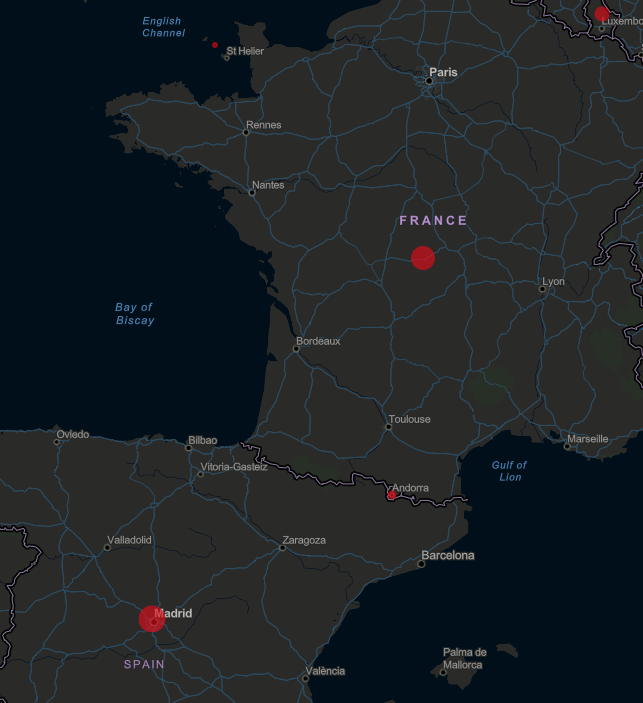
In this example, you’ll note that the dots for Spain and France are also roughly the same size, yet France has roughly half the number of confirmed cases as Spain, 16,689 to 33,089 respectively. I’m not sure whether they are using some sort of logarithmic scale to determine the size of the dots, but ultimately, this map misrepresents the data because the size of the dots does not appear to have a direct correlation with the underlying data.
What bothered me more about this visualization is that it could tell a much richer story with the available data, but does not. For instance, in some countries, the death rate seems to be much higher than others, which begs the question why?
Anyone who has studied data visualization has encountered the work of Dr. Edward Tufte. One of Dr. Tufte’s principles for effective visualization is that effective visualizations should show relationships and changes. This map does not, which ironically is one of the key data points that is of immediate interest to anyone at the moment.
Where is the Curve?
When I look at this information, the area which I am most curious about is how these points are changing over time? We keep reading news articles about “flattening the curve” which can be accomplished by social distancing, etc. The idea being that we can keep the total number of cases below the threshold at which the medical system gets overwhelmed. If that is the metric that matters, why aren’t we seeing line charts with time on the X-axis and the number of cases on the Y-axis?
To answer that question, I used the aforementioned script to clean the Hopkins data and created some dashboards, which if anyone wants I will be happy to publish. As of 22 March, here are a few curves I calculated:
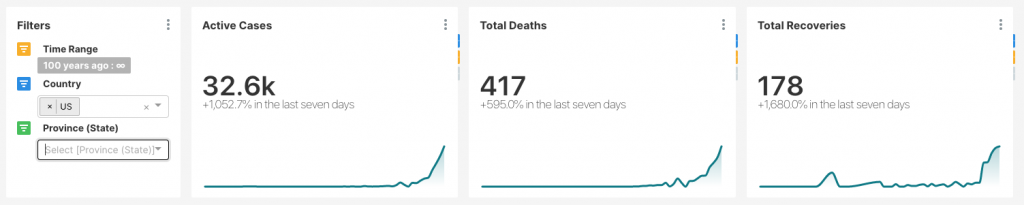

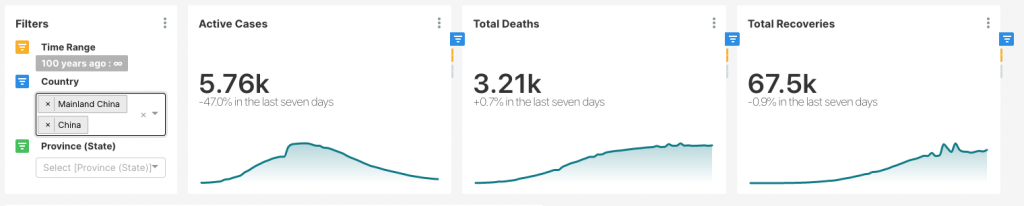
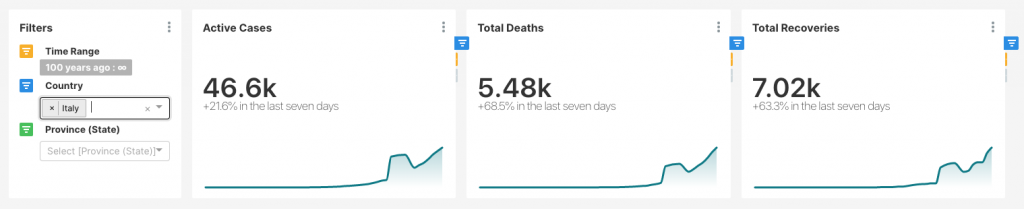
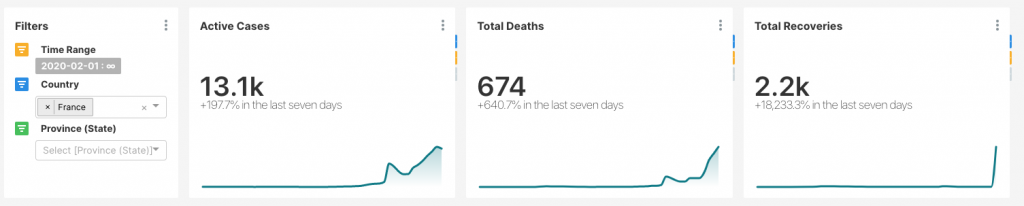
These curves are calculating the total active cases over time. Active cases are calculated by subtracting the recoveries and deaths from the total confirmed cases. I have not completed this analysis yet, but what you see is that most countries, the counts are climbing. I am also interested in death and recovery rates and would like to see how they are changing over time.
Other Missing Metrics
There are a lot of other data points which are simply not available which I believe could help the public better understand the situation. For instance, there is no demographic information publicly available about the individuals who have contracted COVID-19. (Privacy may be a factor here, but I would think the data could be anonymized). Secondly, while we have the counts of confirmed cases, deaths, active and recoveries, we do not have hospitalization count. To me, this is a crucial metric as we can see how many individuals are sick enough to require hospitalization. Tracking this metric would be vital as this will enable municipalities to predict the stress on their local health care systems.
TL;DR
Above all, everyone should stay safe and listen to medical professionals. I do wish that more data was being made available so that the public can better understand this public health crisis.
Hello, I find your site very intriguing and for the most part, way over my head. In reading this post, I wondered of you have seen or heard of this site : https://ncov2019.live/data
It is being touted as the primary source of real time information.