There is a data format called HDF5 (Hierarchical Data Format) which is used extensively in scientific research. HDF5 is an interesting format in that it is like a file system within a file, and is extremely performant. However, the HDF5 format can be quite difficult to actually access the data that is encoded in HDF5 format. But, as the title suggests, this post will walk you through how to easily access and query HDF5 datasets using my favorite tool: Apache Drill.
As of version 1.18 Drill will natively support reading HDF5 files.
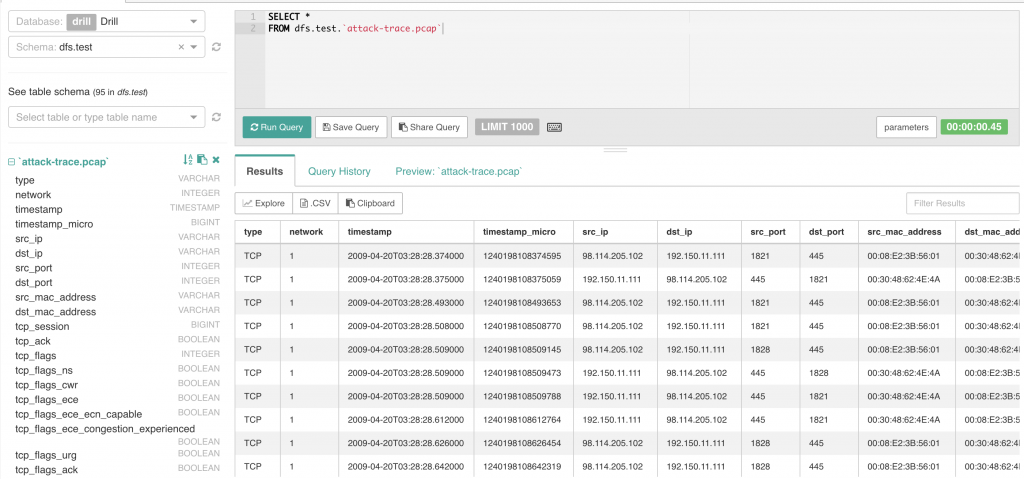
I have been working on using Apache Drill for security purposes and I wanted to demonstrate how you can use Drill in a real security challenge. I found this contest which included a PCAP file of an actual attack, as well as a series of questions you would want to answer in order to the analysis. (https://www.honeynet.org/node/504)
My thought here is that Drill’s advanced ETL capabilities are not terribly useful if you can’t use Drill to do basic stuff that tools like Wireshark can do already, so I wanted to see if it would work in real life. This example was good because I also had “the answers” so I could see how Drill stacks up to the contest winners.
First, I had to see if Drill could actually read the PCAP. The PCAP reader can be a bit wonky, but fortunately, Drill read it without issues! (Whew!). For these examples, I will be using Drill and Superset.
Part one will contain a demonstration of how to use Drill to answer the questions in the first part of the challenge.
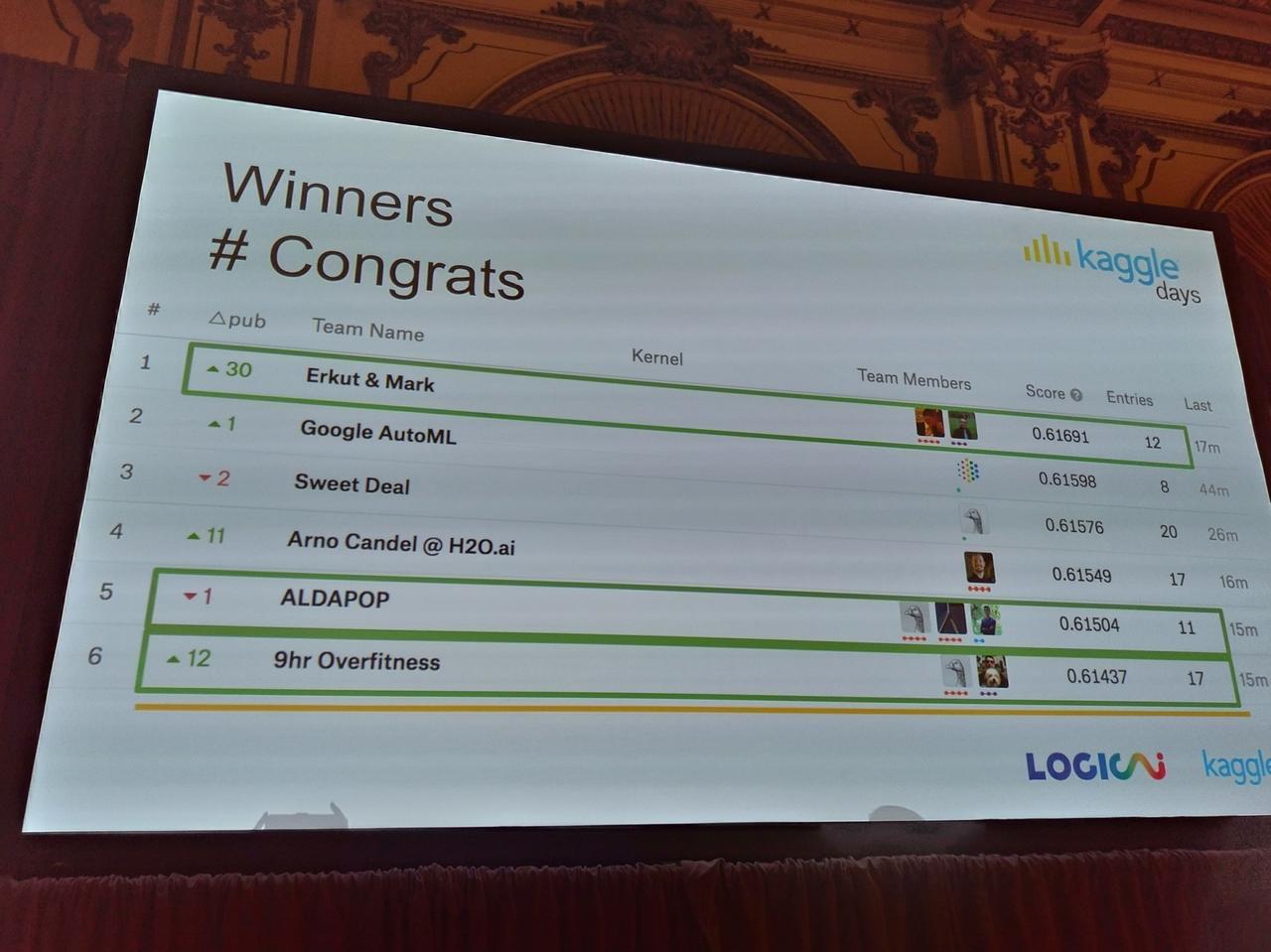
I saw this image on LinkedIn a few days ago and realized that it is proof of the future of data science. The image is of the leaderboard from a Kaggle competition, which isn’t particularly remarkable, but what is remarkable is the competitor in 2nd place: Google AutoML. Not only did AutoML come in 2nd, but it did so in fewer entries and the score was 0.00093 off of first place.
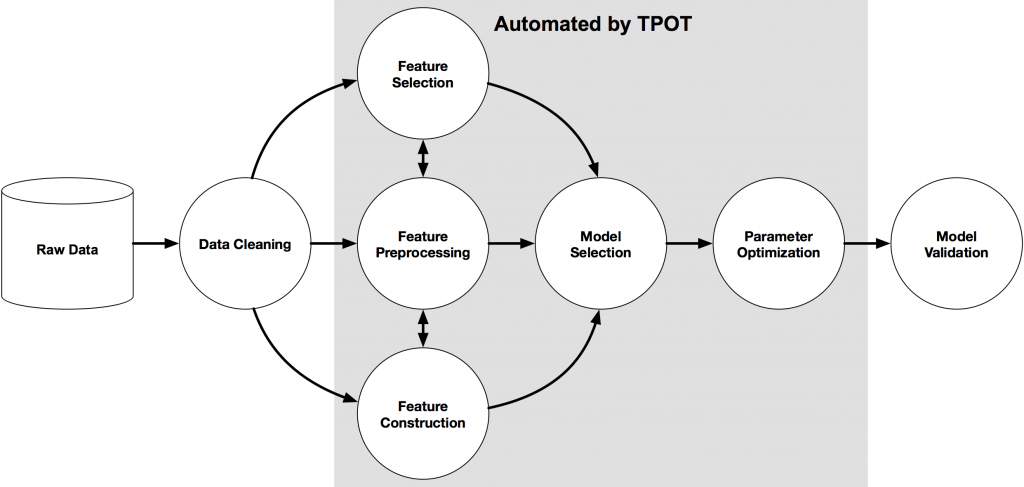
You might be thinking, “Well that’s Google, and they have the best stuff. Technology like that will not be available to the masses anytime soon, and if it is, it will require massive clusters.” Au contraire mon frère. There are a slew of new Python modules which automate various phases of the machine learning process. My personal favorite of which is called TPOT. TPOT is a Python module which automates the entire machine learning process, and generates python code for your entire pipeline.
I did a little experiment with TPOT and was able to build a model with data from Kaggle that scored in the top 10 for a simple exercise.
At some point, Google will likely make their AutoML available to the public if it isn’t already, and data scientists will have to prove that their value over automated machine learning tools.
So What?
The significance of this is enormous. Since the coining of the term data science, many people have focused very heavily on the math and machine learning aspects of data science. These aspects are certainly important, but these steps can be automated, as you can see, with ever improving performance. What this means in the long run is that as available computing power increases and these tools get better and faster, the understanding of the inner workings of the algorithms will become less and less important. (This is not true if you are working at a really cutting edge company that is developing new algorithms, or doing academic research.)
Therefore, if you are a data scientist or an aspiring data scientist, should you quit now? Hardly. Automated ML is really exciting because it will enable you to focus on the things that computers can’t do, and likely won’t ever be able to do, which are: conceiving and defining data problems, communicating the results to stakeholders, as well as the data cleaning/feature engineering steps. Automated machine learning will enable or force data scientists to focus on tasks that truly require human thought and using data science to add value to their organizations.
Well, we did it. I finally finished the book that I had been working on with my co-author for the last two years. I thought I’d write a short post on my experiences writing a technical book and getting it published. I know many people think about writing books, and I’d like to share my experiences so that others might learn from lessons that I learned the hard way. Overall, it was an absolutely amazing experience and I have a feeling that the adventure is only beginning….
I am currently attending the Splunk .conf in Orlando, and a director at Accenture asked me this question, which I thought merited a blog post. Why don’t data scientists use or like Splunk. The inner child in me was thinking, “Splunk isn’t good at data science”, but the more seasoned professional in me actually articulated a more logical and coherent answer, which I thought I’d share whilst waiting for a talk to start. Here goes:
I cannot pretend to speak for any community of “data scientists” but it is true that I know a decent number of data scientists, some very accomplished and some beginners, and not a one would claim to use Splunk as one of their preferred tools. Indeed, when the topic of available tools comes up among most of my colleagues and the word Splunk is mentioned, it elicits groans and eye rolls. So let’s look at why that is the case:
Someone recently asked me for assistance with a university project whereby they were asked to predict whether a given article was fake news or not. They had a target accuracy of 70%. Since the topic of fake news has been in the news a lot, it made me think about how I would approach this problem and whether it is even possible to use machine learning to identify fake news. At first glance, this problem might be comparable to spam detection, however the problem is actually much more complicated. In an article on The Verge, Dean Pomerleau of Carnegie Mellon University states:
“We actually started out with a more ambitious goal of creating a system that could answer the question ‘Is this fake news, yes or no?’ We quickly realized machine learning just wasn’t up to the task.”
Last Friday, the Apache Drill released Drill version 1.14 which has a few significant features (plus a few that are really cool!) that will enable you to use Drill for analyzing security data. Drill 1.14 introduced:
A logRegex reader which enables Drill to read anything you can describe with a Regex
An image metadata reader, which enables you to query images
A suite a of GIS functionality
A collection of phonetic and string distance functions which can be used for approximate string matching.
These suite of functionality really expands what is possible with Drill, and makes analysis of many different types of data possible. This brief tutorial will walk you through how to configure Apache Drill to query log files, or any file really that can be matched with a regex.
As more and more research is showing that the open office design actually reduces productivity (here) and (here), I recently shared a post on LinkedIn about how github “de-broed” their workspace, but I thought I’d share my thoughts on what I like, and don’t like in a work space. Above is a picture of my home office with some labels. Not specifically labeled is that there is plenty of natural light. One of the most depressing places I ever worked was a windowless cube farm where the developers liked to leave the lights off. I was going out of my mind!!
A Door: My ideal workspace has a door so that when privacy is needed, I can close the door and when it is not, I can open it.
A clock: I know computers have clocks, but having a big visible clock is really helpful for making sure things run on time.
A comfortable chair, with foot rest: If I’m doing tech work for a long time, I don’t want to be sitting on something that will cause trips to the chiropractor.
Big Monitors: I’m a big fan of multiple, large monitors, as they really increase productivity.
Music: I like to listen to music, especially when coding. When I’m working in more public spaces, I have headphones…
Stress Relief: I play trombone and when things get stressful, one can always reduce some stress by playing some Die Walkure …. LOUDLY.
Lots of Geek Books:Nothing sets the stage for coding than being surrounded by O’Reilly geek books.
Family Photos or other Personal Items: I do my best work in a space that feels like my own, so I think it is important that people can have a space with some of their personal items that feels like their own. Hence… I’m not a fan of hoteling or workspaces that set people up to work on large tables.