
One of the big challenges facing many data analysts is joining disparate data sets. Recently at DataDistillr, we assisted a prospective customer with an interesting problem which I thought I’d share. In this case, the customer had data from an internal database which had URLs in it, and was looking to create a combined report with some data from SalesForce. The only key that these data sets had in common was the domains in the URL and the domains in email addresses.
These kinds of problems are exactly the kinds of issues that we built DataDistillr for, so let’s take a look at how we might accomplish this. For this post, I generated some CSVs with customer data, one which had URLs and the other which had emails. Using DataDistillr, the process would be exactly the same whether the data was coming from a files, a SaaS platform or a database.
Step 1: Split the Emails
The first step we have to do is split the email addresses up into the domain and account portion. This is actually pretty easy to do because valid emails must (by definition) contain an @ symbol. The characters to the left of the @ are the account and the characters to the right are the domain. So.. our query would look something like this:
SELECT email, split(email, '@')[1] AS email_domain
FROM ...
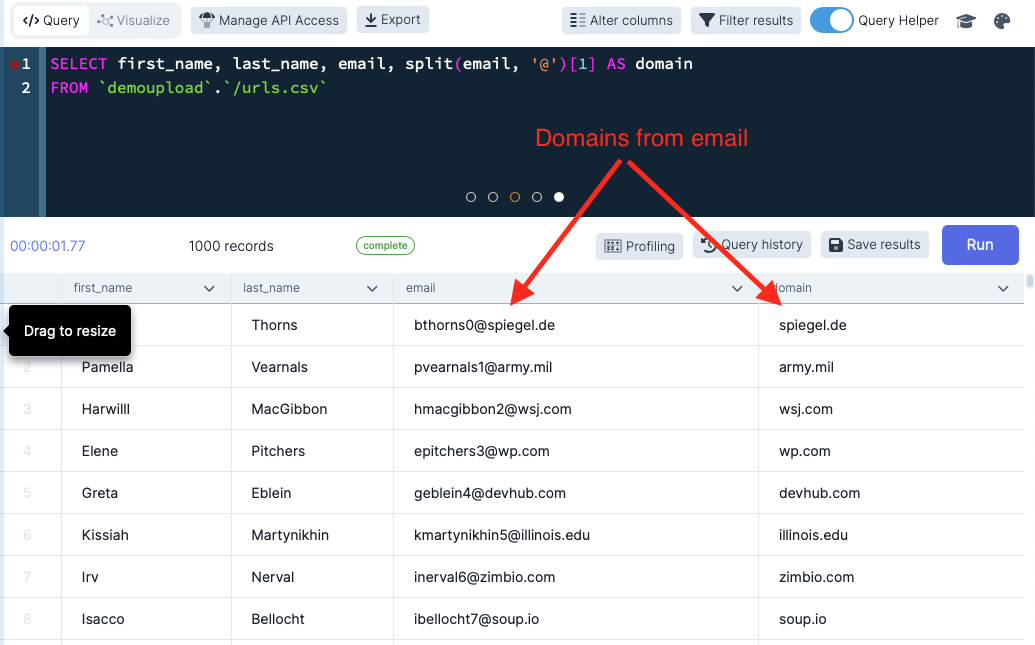
Here we are using the split() function to split the text by the @ and then extract the second part. This will work and it will return the email address and the domain, however it may break if the email column is null or contains an invalid email address. Fortunately, DataDistillr also includes validation functions and we can add a simple check as shown below to only look at records where there is a valid email address:
SELECT email, split(email,'@')[1] AS email_domain
FROM ...
WHERE is_valid(email, 'email')
In this example, we use the is_valid function to determine whether the data in the email column is in fact a valid email address. Easy right? Now let’s move onto the URLs which are a little trickier.
Step 2: Extract the Domain from a URL
Next, let’s take a look at the URLs. This is a bit trickier because there isn’t a single character by which we can just split the string. This is where DataDistillr’s powerful data extraction functions can come into play. In our case, we have a function called parse_url() which, as the name implies, parses URLs into their components.
SELECT parse_url(url) FROM ...
Take a look at the screenshot below:

As you can see, this function splits the URL into the host, path, protocol, filename, authority and query fields. What’s more is that there is an additional function to split up the query string into a collection of key/value pairs, but we don’t need that now….
However, we don’t need the whole collection, just the hostname portion. Now, you might be wondering, doesn’t this go against the principles of data normalization and all that? After all, SQL is meant to be used on databases in normal form and as we all remember from the database classes that we slept through, that in 3rd normal form, fields should only have one value in them.
Accessing Nested Fields in SQL
Since DataDistillr applies a SQL layer over any data, there has to be a way to interact with complex fields such as maps and arrays. I’m not going to go through all that here, but in order to access an inner field in a complex object, you can simply use bracket notation. So in the example above, if we wanted to access the host field, all we’d have to do is:
parse_url(url)['host'] which accesses the host field within that map. If the field is missing, DataDistillr will return null.
Now that we know how to access the inner fields we can write a query to do exactly that to verify that it works.
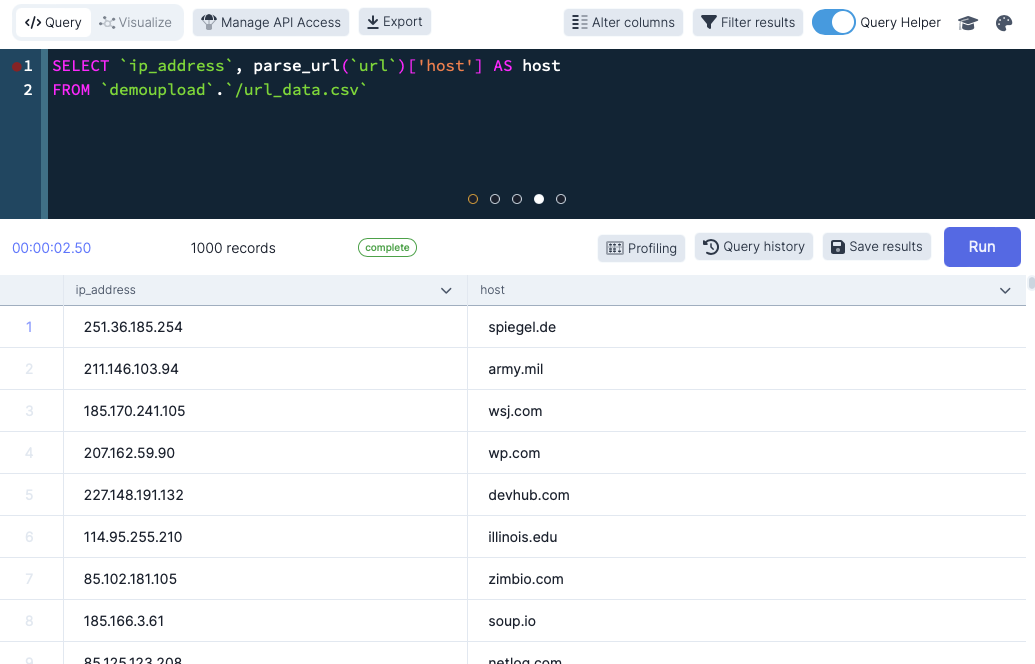
It would probably be smart to validate the URLs as well.
Joining the Data
Now that we understand how to extract the domain from both the email and the URLs, joining the two datasources is as straightforward as writing a SQL JOIN query. In this case, the “magic” happens here: split(customers.email, '@')[1] = parse_url(urls.url)['host'] where we compare the two extracted domains. The complete query is shown below:
SELECT *
FROM `demoupload`.`/customers.csv` AS customers
INNER JOIN `demoupload`.`/url_data.csv` AS urls
ON split(`customers`.`email`, '@')[1] = parse_url(urls.url)['host']
Here are the actual results.
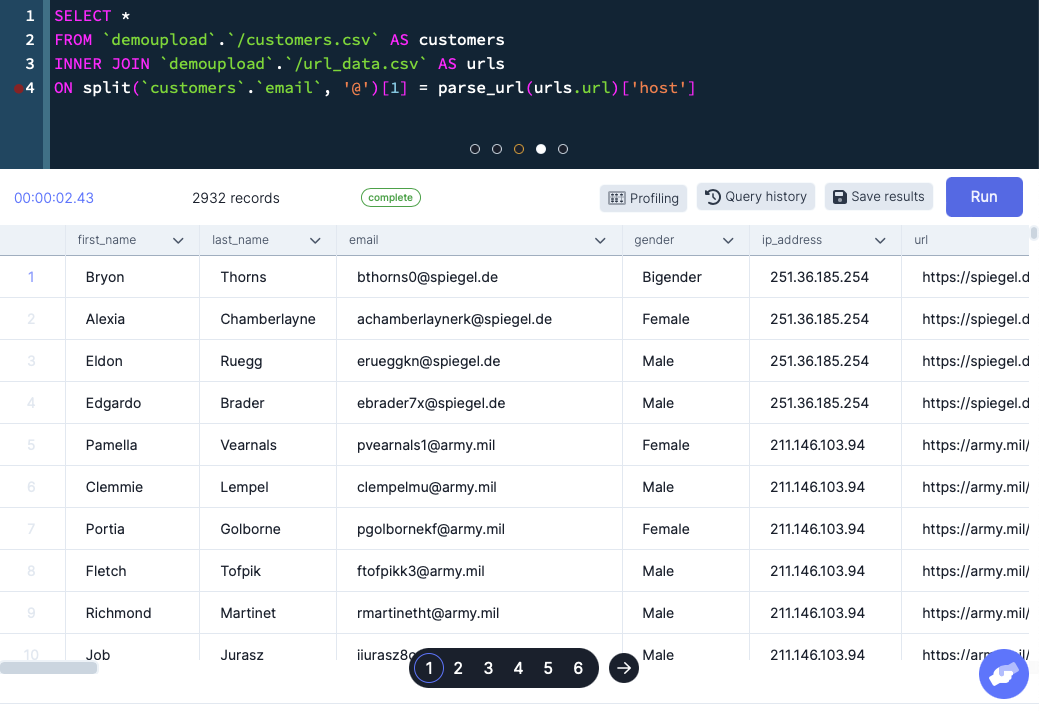
Since this is just generated data, there really aren’t any insights to be had here. If this was real data however, there are a lot of insights we could glean from this. For example, we could look at the various domains and see if there are any patterns there.
TL;DR
In conclusion, DataDistillr makes it possible to join disparate datasets, even when they don’t have a common key. You can see in the tutorial above how easy we make it. If you’re interested in trying it out, we’ll be opening our public beta in a few weeks!!