
My Medium feed thankfully has returned to tech articles and one popped up that caught my attention: Data Analysis project- Using SQL to Clean and Analyse Data. I created my startup DataDistillr to help in such situations and I was wondering could we accomplish the same tasks in less time and effort. In this article, the author takes some data from Real World Fake Data in a CSV file and does the following:
- Step 1. Create a MySQL database from the CSV file
- Step 2. Load the CSV file into the database
- Step 3. Clean the data
- Step 4. Exploratory Data Analysis
- Step 5. Create a dashboard
I thought it would be a great example of how DataDistillr can accelerate your time to value simply by walking through this use case using DataDistillr.
Step 1: Skip Steps One and Two
Here’s the cool part. Using DataDistillr, we can skip steps one and two. All we have to do is upload the file. Technically, since this data is hosted on data.world, we could actually query that data directly w/o even doing that, but for this example, we’re going to download the data and upload it to DataDistillr. Since this is very straightforward, we’ll skip that step, but you can read about how to upload files in the DataDistillr documentation.

You can see in the screen shot above that DataDistillr automagically figured out the schema of the CSV file. By running a simple SELECT * query we can sample the data and see what the first rows look like as well.
Step 3: Exploratory Data Analysis
The next step is figuring out the shape of the data. The original author does this by running some INFORMATION_SCHEMA queries. That is not necessary in DataDistillr as the columns are viewable in the nav tree, and simply running the original SELECT * query will tell you how many rows you have.
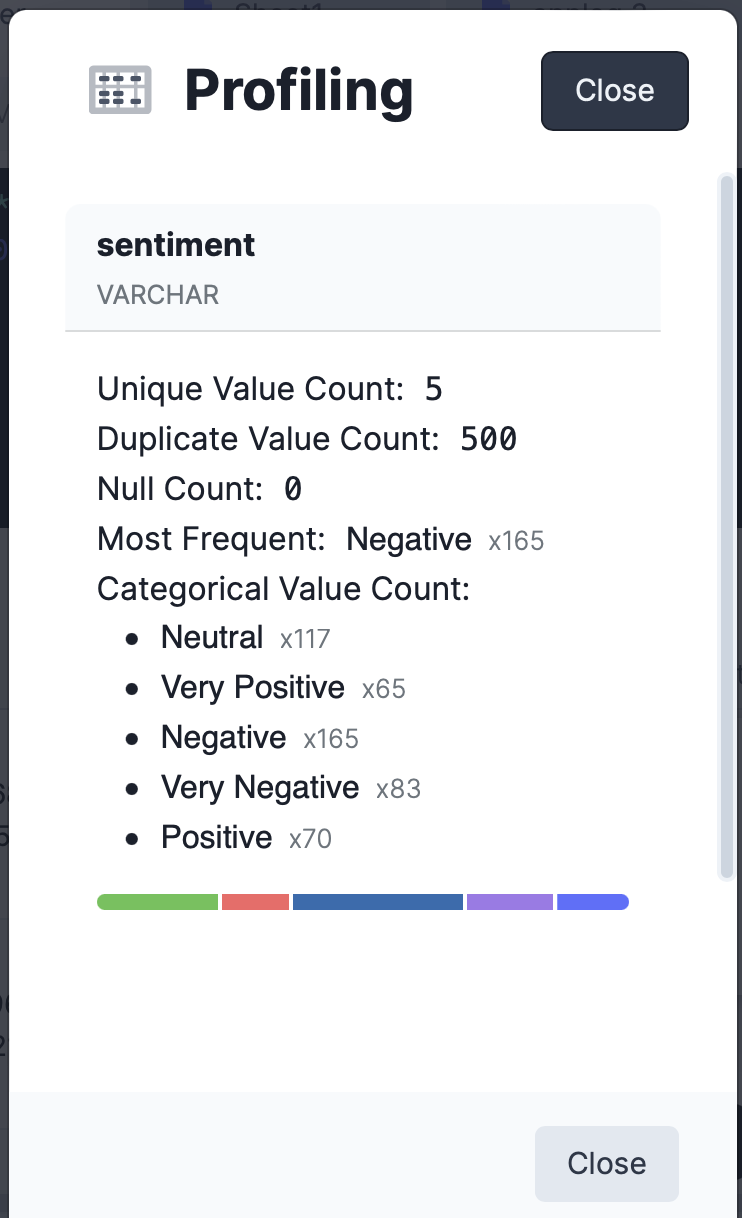
The next step the author does is to count the values in some columns by running a number of SELECT DISTINCT queries. DataDistillr saves you time on this front as well. As we are scanning the data, DataDistillr calculates summary descriptive statistics about each column, as shown on the left.
As you can see, this is a major time saver in that you don’t have run additional queries for every column that you wish to summarize.
Once this is done, the author executes a series of queries which involve aggregating and counting values in columns. Some of these can be accomplished with the column summary view, but others are exactly the same in DataDistillr so we’ll skip them here. As you can see in the screen shot below, the results are basically the same.
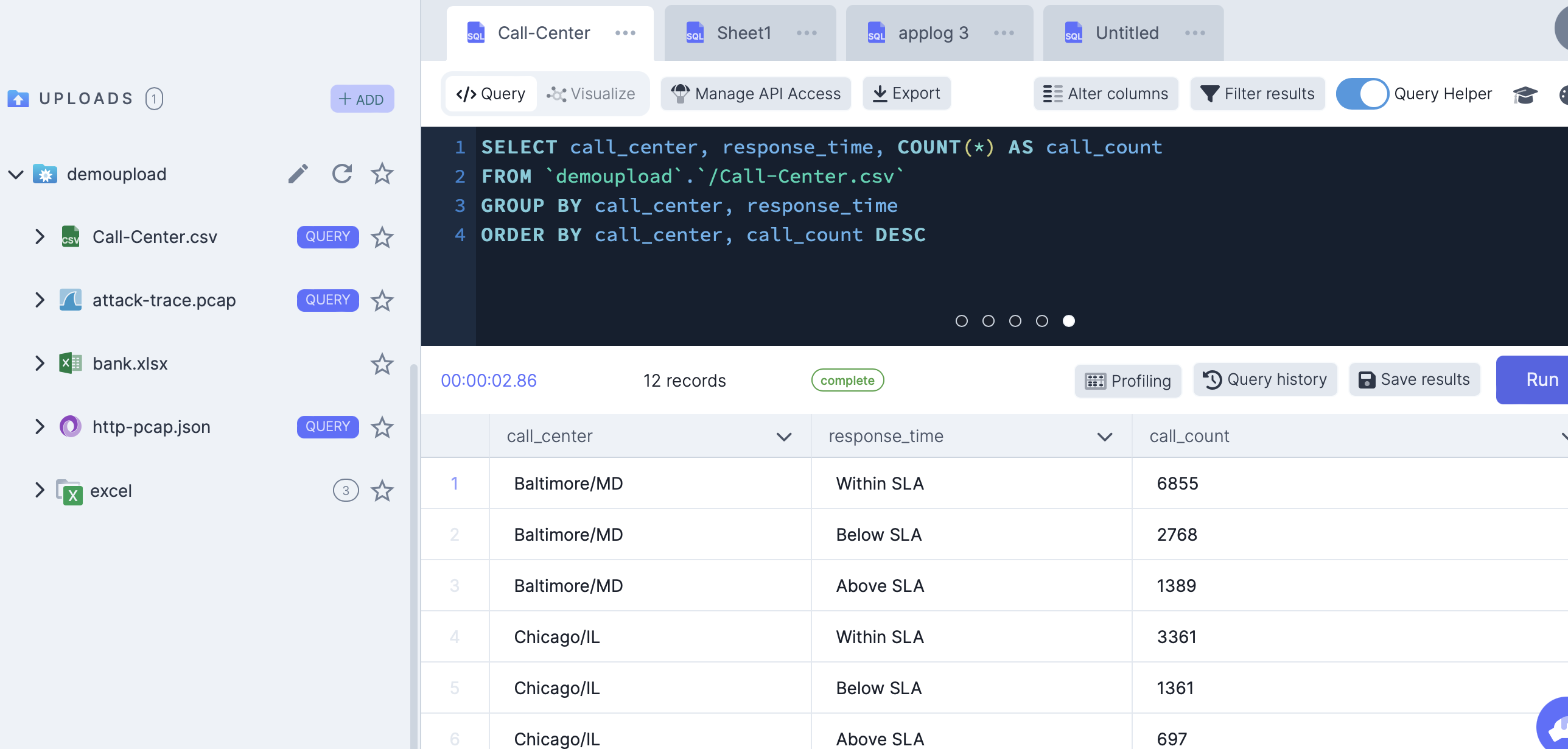
The last query, the author uses a windowing function to figure out the maximum call duration per day. I wasn’t sure why he chose to do this as the query below will do the trick without window functions. I ran this query and got different results from the author. After further investigation, I found that the author’s query with the window function was not correct. I’m not sure what it was doing, but what I found was that for most days, the max call length was 45 min.
SELECT call_timestamp,
MAX(CAST(call_duration_in_minutes AS INT)) AS max_call_length
FROM `demoupload`.`/Call-Center.csv`
GROUP BY call_timestamp
ORDER BY max_call_length DESC
Step 5: Visualizing The Results
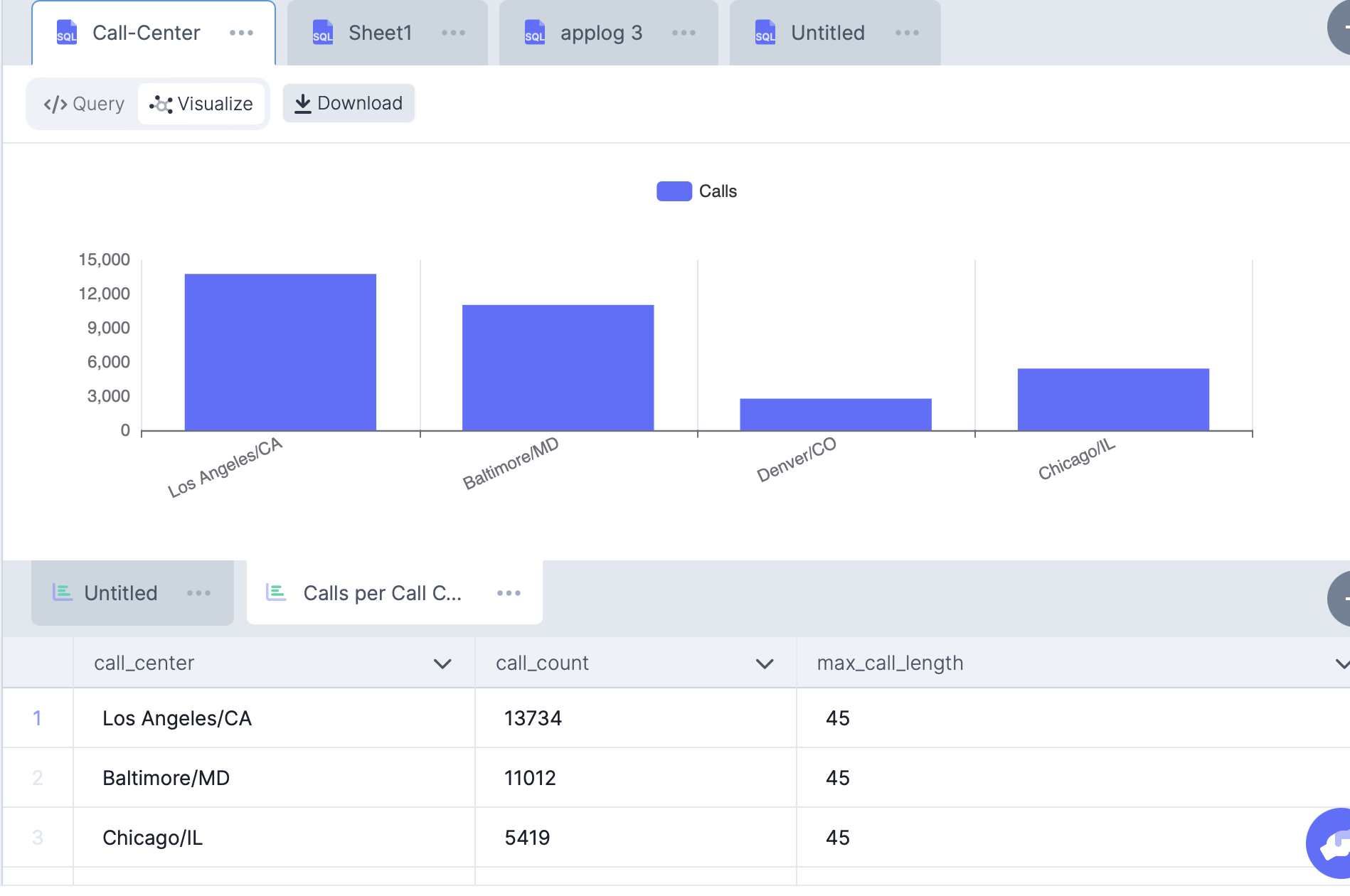
The final step is to visualize the results. The author used Tableau for this and created a public dashboard. DataDistillr has a web data connector for Tableau and thus, you could do exactly the same thing but using DataDistillr as your data source. Alternatively, you can visualize the results right in DataDistillr. The screenshot below demonstrates what that might look like.
TL;DR
As you can see, with DataDistillr, you can quickly analyze tabular data such as that found in a CSV files, using standard SQL, without having to create databases or move data around. In the next example, I’ll show you how you can pull data directly from an API and do the same thing! If you are interested in kicking the tires, please submit the form for our private beta!