
One of the biggest challenges in data science and analytics is… well… the data. I did a podcast and the interviewer (Lee Ngo) asked me a question about challenges in data science. We were talking and I told him that it reminded me a lot of a story I heard about immigrants to America in the early 20th century. They came here thinking the streets were paved with gold, but when they arrived, they discovered that not only were the streets not paved with gold, they were not paved at all, and they were expected to pave them. What does this have to do with data?
Well, it always surprises me when new data scientists or data analysts are surprised when they start a project and the data is rubbish. Especially when organizations are early in their data journey, it is very common to have data that is extremely difficult to work with. When this happens, you can either complain about it, as many data scientists are wont to do, or you can roll up your sleeves and start cleaning.
With that said, one of the things that always surprises me is how little data cleaning is often offered in most data tools, which in turn has spawned an entire industry of data cleaning or data quality tools which need to be bolted into your data stack. I’ve always felt this was silly and that this is a basic functionality that analytic tools should just have. So DataDistillr does! But I digress, let’s get back to the original topic of cleaning names.
Names are Dirty
Often when dealing with data, especially manually entered data, you will find that people are lazy and record people’s names as one field. IE: Mr. Charles S. Givre CISSP. This poses several problems. Firstly, if you are trying to do mail merges you will want to break this up by first name, last name etc and you don’t want to address communications as “Dear Mr.” or whatever. Also, there are many data enrichment companies such as People Data Labs that can provide demographic and contact information for a given person. But none of this works if you don’t have the names broken up into first, last, middle etc.
Why is this hard?
Well… you might be thinking… that’s easy, just split up the name by spaces and it will work. This will, until you have an edge case, and believe me… you will. If you split by spaces, you could say that the first word is the first name, and the last word is the last name. This works until you have something like C. Brad Whitfield or something like that. Or, if you are pulling from multiple data sources, inevitably some names will be in first, last format and others will be in last, first format. Which brings up another issue… sorting. If your data is in the aforementioned format of first last, you will not be able to sort this data properly, and by properly I mean in alpha order by last name.
What can you do?
As someone who has wrestled with this problem for some time, I realized that having little features in DataDistillr that can do these kinds of things really makes our tool shine above the rest. Firstly, DataDistillr has a suite of functions that can split up human names. These functions are “smart” enough so that they can figure out that a person’s first name isn’t Dr. or the like. The specific functions are:
* `getFirstName(<name>)`: Gets the first name from the input name
* `getLastName(<name>)`: Gets the last name from the input name
* `getLeadingInitial(<name>)`: Gets the leading initial from the input name
* `getNickName(<name>)`: Gets the nickname from the input name
* `getMiddleNames(<name>)`: Gets the middle names from the input name
* `getNameSuffix(<name>)`: Gets the suffix from the input name (like 'Jr.', 'III')
* `getSalutation(<name>)`: Gets the salutation from the input name (like 'Mr.', 'Mrs.', 'Dr')
* `getPostnominals(<name>)`: Gets the postnominals from the input name (like 'PHD', 'CPA')
Thus, if you have a column in a dataset called full_name you could write a query like this to extract all the name components:
SELECT getFirstName(full_name) AS first_name,
getMiddleNames(full_name) AS middle_name,
getLastName(full_name) AS last_name,
getLeadingInitial(full_name) AS leading_initial,
getNameSuffix(full_name) AS suffix,
getSalutation(full_name) AS salutation
FROM <data>
The best part is that this works with any data source that DataDistillr can query… which would be just about anything. Here’s a screen shot of the results:
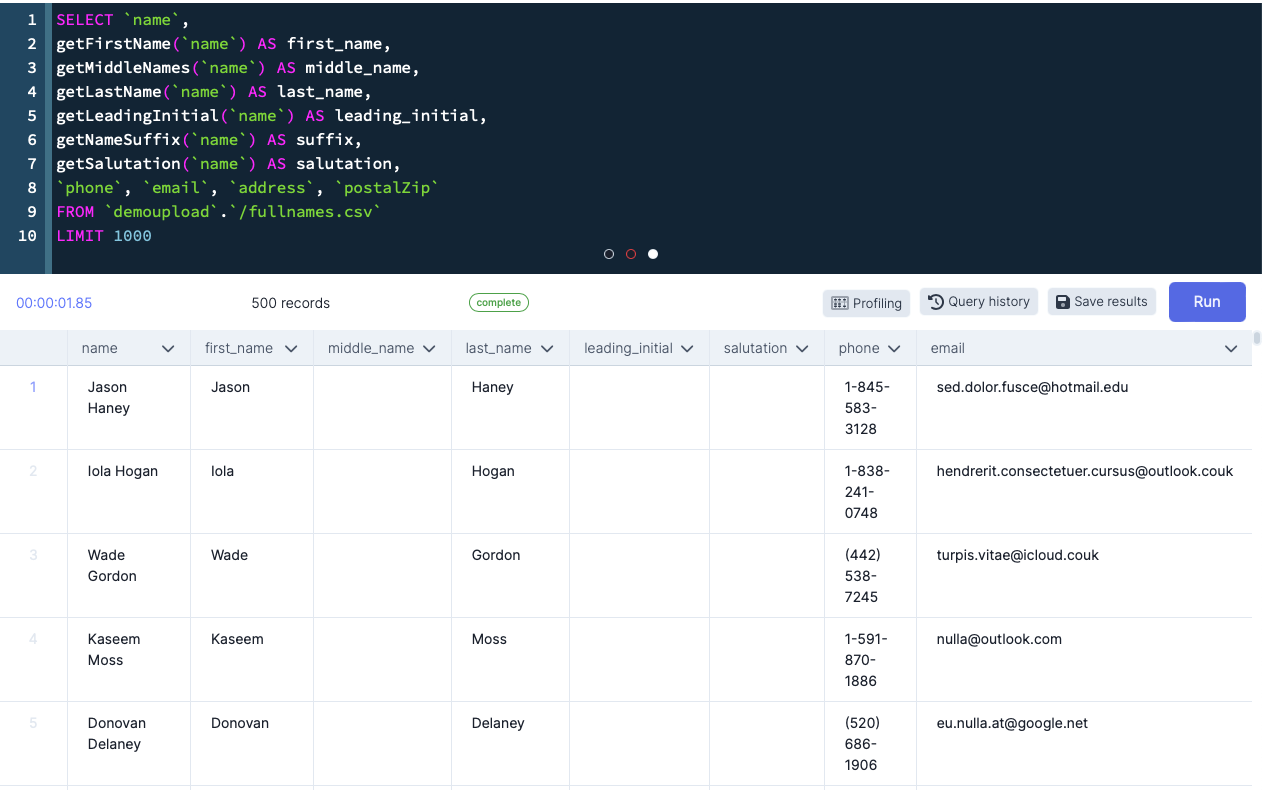
What can you do now that the name is split?
A lot actually. Now that the name is split, you can sort the data properly. You can also enrich the data with external data sources. The pseudo query below demonstrates how you might query people data labs to get information about an individual person:
SELECT <fields>
FROM data.csv AS t1
INNER JOIN people_data_labs AS t2
ON getFirstName(t1.name) = t2.first_name AND
getLastName(t1.name) = t2.last_name
What this query would do is query People Data Labs and return all kinds of demographic information for each individual. This same basic idea would work for virtually any enrichment API.
What’s more is that we also have functionality which can guess the gender of a person based on their name. This is only a guess and clearly doesn’t cover gender fluid or trans individuals but you might be able to glean some insights as to the gender breakdown of a client base.
If you’d like to give this a try, please sign up for our private beta.