
There is a data format called HDF5 (Hierarchical Data Format) which is used extensively in scientific research. HDF5 is an interesting format in that it is like a file system within a file, and is extremely performant. However, the HDF5 format can be quite difficult to actually access the data that is encoded in HDF5 format. But, as the title suggests, this post will walk you through how to easily access and query HDF5 datasets using my favorite tool: Apache Drill.
As of version 1.18 Drill will natively support reading HDF5 files.
Configuring Drill to Query HDF5
In order to configure Drill to query HDF5 files, you will first have to set the following variables in the configuration for your file system. This should work with HDF5 files that are stored on Hadoop, S3/Azure/Google Cloud, or a local file system. This will also work with compressed HDF5 files. The only variable that isn’t self-explanatory is the defaultPath, which I’ll get to later, but for now leave it as null.
"hdf5": {
"type": "hdf5",
"extensions": [
"h5"
],
"defaultPath": null
}
Once you’ve added this to the config, Drill is ready to query HDF5.
Querying HDF5 Files in Drill
Now that Drill is set up, you can query HDF5 files directly in Drill. However, Drill queries HDF5 in two ways: a metadata query and a data query. The metadata query allows you to explore the contents of the HDF5 file–remembering that an HDF5 file will contain multiple datasets–and the data query lets you directly query a dataset. Let’s first take a look at metadata queries. The way you determine whether Drill will execute a metadata or dataset query is by setting the aforementioned defaultPath variable. When it is set to null, you get file metadata, so for now, we will leave it as null, and see what happens.
In this example, we will query a file called scalar.h5 which is a simple file that contains a few sample datasets. At a minimum, the metadata query will return the following fields:
- path: This is the HDF5 path to an individual dataset. When you want to query a dataset, this is the value that you will set in the
defaultPathvariable. - data_type: This the type of object contained in the particular path. Options are GROUP, DATASET, SOFT_LINK.
- file_name: The name of the actual file.
- attributes: HDF5 datasets can have attributes. Drill maps these to a map of key/value pairs.
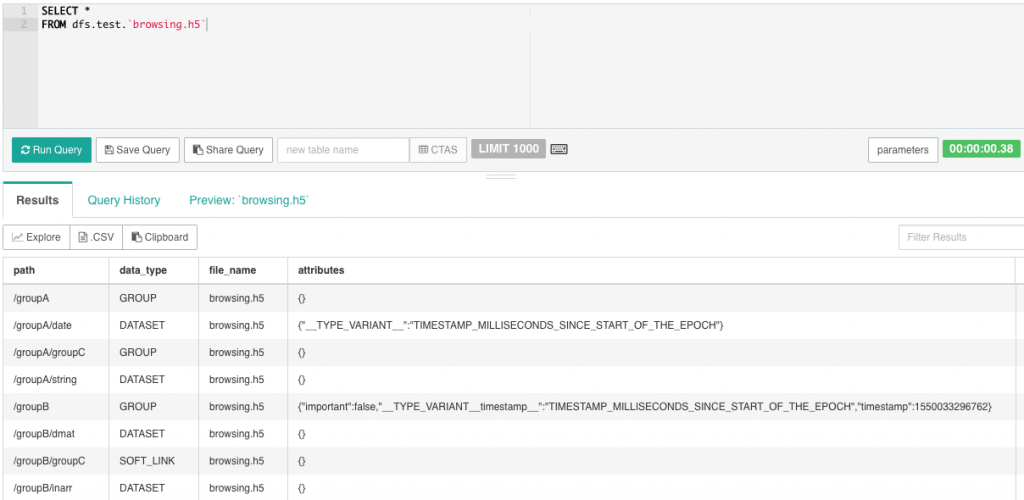
In addition to the metadata, the metadata queries will also return the actual dataset. The data will have a field name of <data type>_data. So in this example, there is a column called double_data which contains a nested list of the actual data.

You could query this data directly with the query below, however, that is not efficient and will result in extremely complicated queries.
SELECT flatten(double_data)
FROM dfs.test.`browsing.h5`
WHERE path='/groupB/dmat'
A better way to query this dataset is to use the defaultPath option which I’ve avoided discussing until now.
Querying Datasets
In addition to querying HDF5 file metadata, Drill will also allow you to query individual datasets within an HDF5 file simply by setting the defaultPath option in the HDF5 configuration. This can be done either in the configuration directly, or at query time using the table() function. For example, if you wanted to query the dataset above, you could do so with the following query:
SELECT *
FROM table(dfs.test.browsing.h5 (type => 'hdf5', defaultPath => '/groupB/dmat'));
You will note the use of the table() function which sets the defaultPath to /groupB/dmat. The results of this query are shown below.
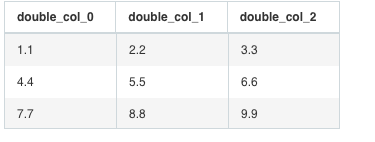
As you can see, this query produces three columns which reflect the type of data: double_col_n. These columns can then be selected individually, filtered, aggregated, used in a function or combined in any other way with any data that Drill can query.
One thing to point out is that HDF5 supports nested data of unlimited dimensions. While Drill does as well, the practical implications of this are data that becomes unwieldy, so Drill will automatically flatten any data that is more than 2 nesting levels deep.
How Fast Is It?
That is the question isn’t it? Well I have one word… FAST! Unfortunately, the HDF5 libraries have a significant limitation which I’m not going to get into here, but if and when that limitation gets fixed, this thing will be even faster!! I did some tests with actual HDF5 data files and on my Macbook, Drill was able to query a large dataset in a 1GB HDF5 in under 2 seconds. More importantly however is not just “how fast is it” but “How easy is it?” In my opinion this where Drill really shines. Querying HDF5 data with Drill is super simple since Drill uses standard SQL. It makes it as if your HDF5 data was just another table in a database!
TL;DR
In conclusion, if you are doing scientific research and deal with HDF5 data but don’t want to deal with HDF5 libraries, or coding, or simply prefer to use SQL, you really should give Drill a try. Drill can easily and performantly query HDF5 datasets as if they were a regular database table. There you go!
When does Apache Drill 1.18 come out ?
We’re shooting for mid Q2. You can get the snapshot and build that.