Happy New Year everyone! I’ve been taking a bit of a blog break after completing Learning Apache Drill, teaching a few classes, and some personal travel but I’m back now and have a lot planned for 2019! One of my long standing projects is to get Apache Drill to work with various open source visualization and data flow tools. I attended the Strata conference in San Jose in 2016 where I attended Maxime Beauchemin’s talk (slides available here) where he presented the tool then known as Caravel and I was impressed, really really impressed. I knew that my mission after the conference would be to get this tool to work with Drill. A little over two years later, I can finally declare victory. Caravel went through a lot of evolution. It is now an Apache Incubating project and the name has changed to Apache (Incubating) Superset.
UPDATE: The changes to Superset have been merged, so you can just install Superset as described on their website.
The Challenge: Some Backstory
When I got back from Strata, I attempted to get Drill to connect to Superset but immediately ran into trouble. Superset uses SQLAlchemy as a data abstraction layer. If the technical details don’t really interest you, you can skip this section, but if not, read on…
SQLAlchemy is an Object Relational Mapper (ORM) and uses what are known as dialects to connect to various data sources. Problem 1: There was no SQLAlchemy dialect for Apache Drill. So at this point I saw that John Omernik had already started working on an SQLAlchemy dialect, but it wasn’t working completely. Around the same time, two developers released PyDrill and DrillPy, which were two Drill drivers for Python that used the REST interface. From what I recall, the original iteration of the SQLAlchemy dialect used ODBC, which I’ve found to be difficult to use, so I attempted to rewrite John’s dialect to use PyDrill, which led me to Problem 2: There was no PyDBAPI compliant driver for Drill.
So… in order to get any of this to work, I first had to write a Python DB-API compliant driver for Drill, then write a SQLAlchemy dialect then maybe, just maybe Superset would work with Drill. I worked on this for a while, and eventually, John Omernik revised the SQLAlchemy dialect so that it was able to connect to Superset, however there were some challenges and it didn’t work very well at the time. Around then, I switched jobs and didn’t have time to keep working on it. I think the same happened with John, so the project languished for a bit.
However, after finishing the Drill book, I really wanted to get this to work properly, so I decided to have another go at it. One of the big challenges I faced when working on the dialect is that when you are using the REST interface is that Drill does not provide column metadata after executing a query. Meaning that when you execute a query using the JDBC or ODBC interface, a database will return metadata about the results including the column names and data types. Drill does this in the JDBC or ODBC interfaces, but did not for the REST interface. To get Superset to work with Drill, I had to fix this, so I submitted a small pull request so that Drill will return column metadata when you execute queries via the REST interface. As of Drill 1.15, you get results as shown below which includes column metadata.
{
"queryId": "23b17468-2ce1-4c5b-48e3-d08a1f0ec785",
"columns": [
"employee_id",
"full_name",
"first_name",
"last_name",
"position_id",
"position_title"
],
"rows": [
...
],
"metadata": [
"INT",
"VARCHAR",
"VARCHAR",
"VARCHAR",
"BIGINT",
"VARCHAR"
]
}
Column metadata is vital for visualization tools such as Superset because Superset needs to know what kind of data to expect in order to properly visualize it. Now that the metadata is available, I went back and worked with John to integrate this functionality into the SQLAlchemy dialect. There were still other challenges to complete the integration, but I’ll spare you the details.
Installing Superset
I’ll start by assuming that you have a working installation of Apache Drill on your machine. You will also need to have a reasonably current version of Python installed on your machine. To install SQLAlchemy, simply use pip to install it via:
pip install sqlalchemy
Next, you’ll need to get the Drill SQLAlchemy dialect installed. The dialect is available here: https://github.com/JohnOmernik/sqlalchemy-drill. To install it simply execute the commands below:
git clone https://github.com/JohnOmernik/sqlalchemy-drill
cd sqlalchemy-drill
python setup.py install
You’re now ready to install Superset. In case Superset changes, I’ll post a link to the Superset installation instructions here. Once you’ve installed Superset, make sure that it is up and running properly.
UPDATE: The changes to Superset to integrate Drill have been merged, so you can just install Superset as per the instructions on the Superset website.
Connecting Drill to Superset
The book Learning Apache Drill covers connecting to Superset, but doesn’t really get into the use case for Superset and Drill. The first thing to do is navigate to the Sources menu and navigate to Databases.
Note: At the time of writing, I submitted a pull request to Superset which includes a few minor modifications to Superset to enable it to work well with Drill. The PR has not been accepted yet, but I recommend using that version of Superset rather than the “official” version if you want to use Drill with Superset. Here is a direct link: (https://github.com/apache/incubator-superset/pull/6610)
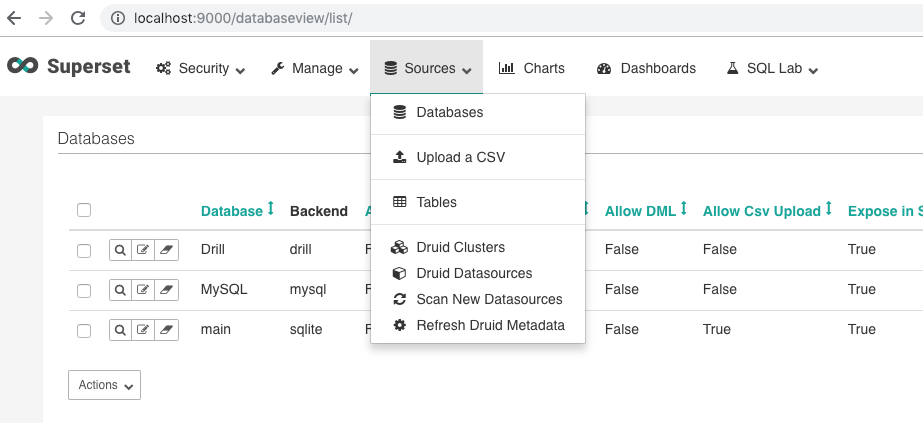
Next, click on the button to add a new database and you will see a screen like the one below. In order to connect to Drill, it goes without saying that Drill must be up and running first. Superset will not allow you to enter a database if it cannot connect, so don’t try this without Drill up and running. The main thing to configure is the SQLAlchemy URI. To connect to Drill, use the following format:
drill+sadrill://<user>:<password>@<host>:<port>/<storage_plugin>/<workspace>?use_ssl=False
To connect to a Drill installation on a local machine, use the following connection string:
drill+sadrill://localhost:8047/dfs/test?use_ssl=False
Make sure you check the box to enable SQL Lab access.
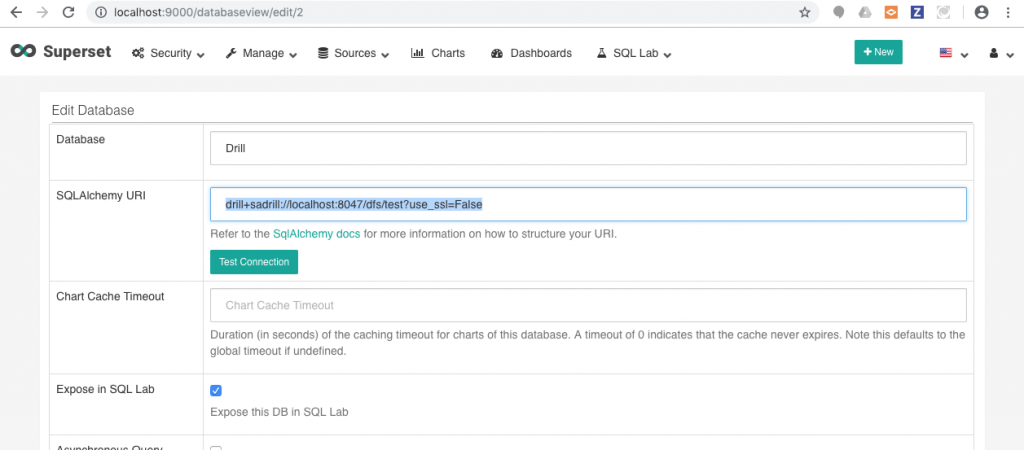
Once you’ve done this, if you click on ‘Test Connection’ you should get a message that the connection succeeded. You’ll see a listing of all the available tables in that storage plugin/workspace combination.
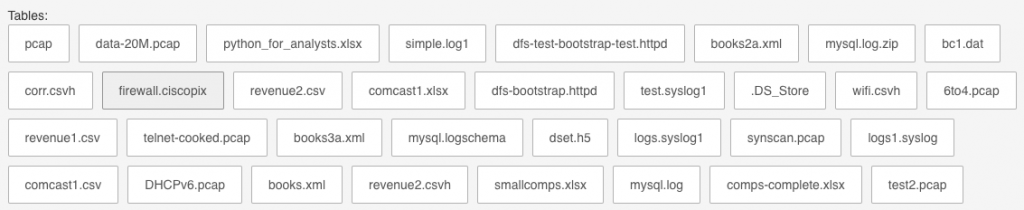
You can add a table to the sources at this point, but if you really want to experience Superset, let’s take a look at SQL Lab.
Exploring Data in SQL Lab
Now that you’ve connected Drill to Superset, let’s start Drilling into data. The first thing you should do in SQL Lab is select Drill from the database drop down. If all went well, the available storage plugins and workspaces should populate the schema menu.
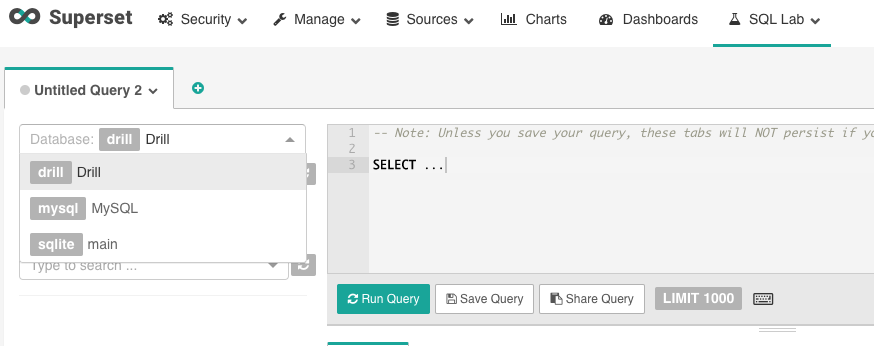
After picking a table schema, you should see a list of columns and their associated data types on the left hand side as well as a preview of the data. In the screenshot below, I loaded a pcap file into Superset using Drill. Pretty cool eh!
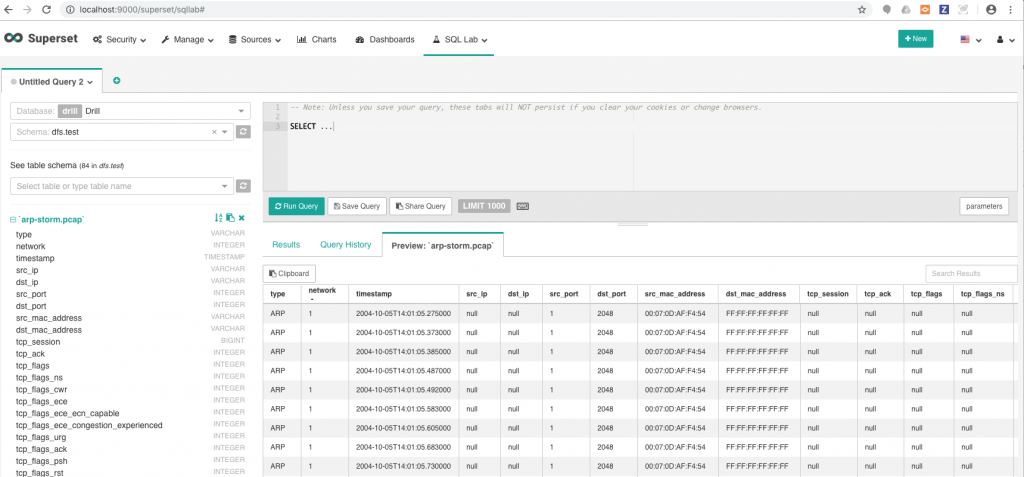
You’re There!
At this point you can begin exploring and visualizing data with Superset! I am very interested in hearing if and how people are using this, so please feel free to drop me a note if this is useful for you!
[…] my goal is to integrate Superset and Drill together. The only tutorial I was able to find was a tutorial from Dataist. When following this tutorial they ask us to add a […]
It looks like you did not install the Drill SQL Alchemy dialect. I believe that once you install that, your installation will work.
I have followed the procedure, As you mentioned but still, it is throwing the error
sqlalchemy.exc.NoSuchModuleError: Can’t load plugin: sqlalchemy.dialects:drill.sadrill
Hi there,
This error means that the sqlalchemy dialect wasn’t installed. If you are running a virtual environment, make sure that you installed the sqlalchemy dialect in the virtual environment. Please try re-installing the sqlalchemy drill dialect and that should fix it for you.
I am facing the same issue, where i have the superset running in my VirtualBox on Windows with Ubuntu. I have Drill running on a hosted server. I installed the sql alchemy as mentioned , but still facing the error.
sqlalchemy.exc.NoSuchModuleError: Can’t load plugin: sqlalchemy.dialects:drill.sadrill
The above exception was the direct cause of the following exception:
superset.databases.commands.exceptions.DatabaseTestConnectionDriverError: Could not load database driver: DrillEngineSpec
Thanks so much for the article. I got Superset (docker) to work with Drill).
The problem that I have are:
1) In SQL editor, I pick the schema but it cannot load table definition for example the Nation.parquet
2) I cannot add the dataset for Nation.parquet so that I can use the chart
Any thought?
I haven’t been able to run supserset (on docker) and connect it with drill, maybe you can help me to answer this question: https://stackoverflow.com/questions/66936316/how-to-connect-apache-superset-with-apache-drill
If you can do it I’ll appreciate it.
[…] This tutorial mentions that, when drill is in embedded mode, the query string is drill+sadrill://localhost:8047/dfs?use_ssl=False. However, when I test the connection I get this error […]
[…] This tutorial mentions that, when drill is in embedded mode, the query string is drill+sadrill://localhost:8047/dfs?use_ssl=False. However, when I test the connection I get this error […]