Happy New Year everyone! I’m pretty excited about this. Like every other tech geek out there, I was experimenting with ChatGPT when it was announced in December of 2022.
Initially I was amazed at how well the AI appeared to work, and somewhat terrified with what people could actually do with it. I teach a database class at the University of Maryland Baltimore County (UMBC) and I was really worried that students could use ChatGPT to generate answers to essay questions on my exams. I wanted to see if there were ways of phrasing questions that would make it obvious that a person did not write them. After using ChatGPT for a while, I do think it would be possible to detect if a student was using AI to write their papers, as the quality and style are fairly distinct.
But I digress…
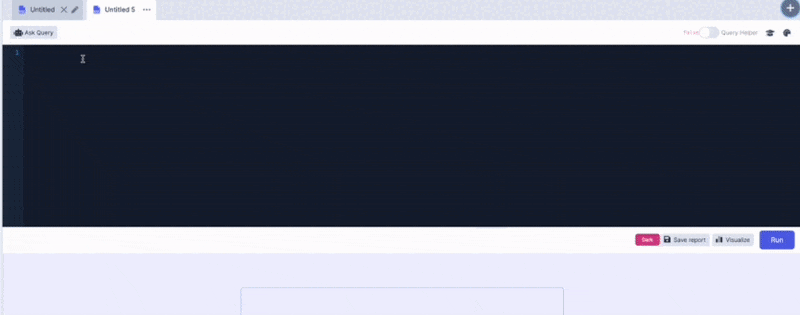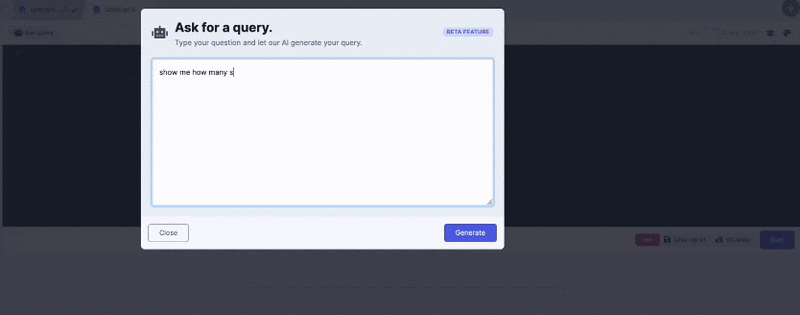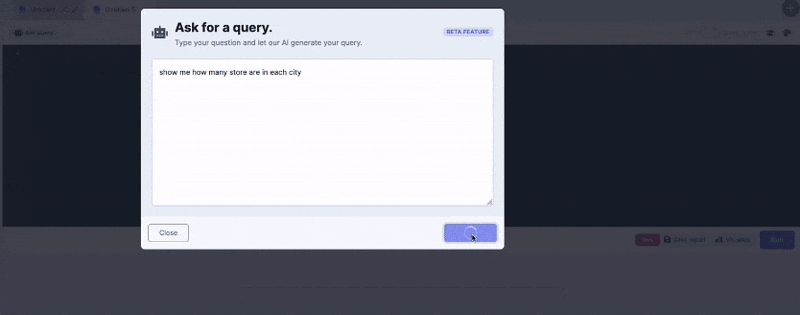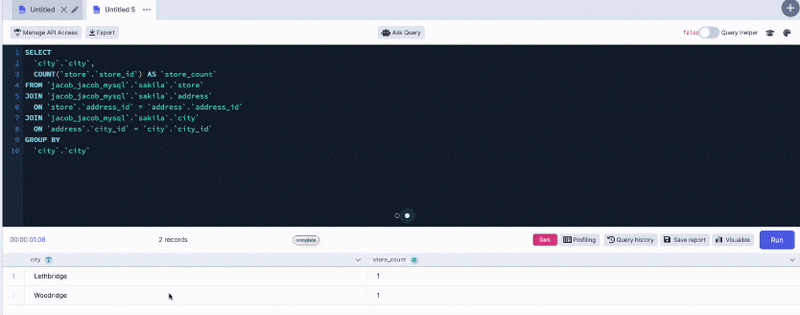
What really intrigued me was that these models can write SQL queries using natural language. Of course the fact that you can write a SQL query isn’t necessarily useful unless you understand the schema of the underlying data and you have a query engine or database capable of executing that query.
Well… guess what…
My team and I have been hard at work at incorporating this powerful feature into our DataDistillr. Today, I am happy to announce that we’ve added natural language AI capability to DataDistillr!
Leave a Comment







